
Auf künstlicher Intelligenz basierende Textgeneratoren wie ChatGPT haben die Aufmerksamkeit einer breiten Öffentlichkeit gewonnen. Wie diese funktionieren, ist jedoch nicht einfach nachvollziehbar. Aus diesem Grund hat der Informatiklehrer Marc Siemering eine didaktisch vereinfachte auf Markow-Ketten basierende Version in Python geschrieben, welche er anlässlich des Ausbaldower-Barcamps am 2. Februar 2023 unter dem Titel „Wir würfeln Wörter“ vorstellte. Dieser Blogbeitrag greift die von Marc Siemering vorgestellten Ideen auf und erklärt diese am Beispiel der blockbasierten Programmierumgebung Snap!
Der Zufall als Grundlage
Damit solche Anwendungen wie ChatGPT überhaupt funktionieren, benötigen sie eine entsprechende Datenbasis. Diese wird aus bereits vorhandenen Texten gewonnen. In der einfachsten Variante (ChatGPT ist wesentlich komplexer), werden diese Texte genutzt, passende Datenstrukturen aufzubauen.
Bevor man sich mit der Auswertung von Texten beschäftigt, lohnt es sich aber, erst einmal einige grundlegende Versuche durchzuführen. Für diese erste Gehversuche eignen sich die Zahlen 0-9. Damit können alle zu schreibenden Blöcke getestet werden, bevor diese auf einen Textkorpus angewendet werden.
In Snap! kann man sehr eine Liste von Zufallszahlen mit folgenden Blöcken generieren:

Die so erzeugten Zufallszahlen können mit einem entsprechenden Block auf dem Bildschirm ausgegeben werden.

Die entsprechende Bildschirmausgabe sieht dann beispielsweise so aus:

Genau das gleiche Vorgehen kann nun anstatt mit Zahlen auch mit den aus einem Text gewonnenen Wörtern verwendet werden (zur Herkunft der Texte später mehr).
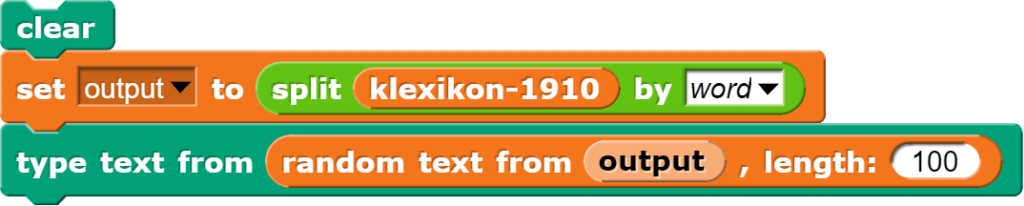
Anstelle der zufälligen Zahlen werden so zufällige Wörter auf dem Bildschirm ausgegeben.

Dass die generierten Wörter thematisch zusammenpassen, hängt damit zusammen, dass diese aus einem Klexikon-Text zum Thema „Steinzeit“ stammen.
Struktur des Textes nutzen
Da es nicht das Ziel ist, zusammenhangslose Texte zu produzieren, soll in einem nächsten Schritt die Abfolge der Wörter im Text genutzt werden, um ein besser passendes Ergebnis zu erzielen. Ob die entsprechenden Programmblöcke richtig funktionieren, kann mithilfe der Snap!-Blöcke ebenfalls schnell anhand der Zufallszahlen überprüft werden. Das Augenmerk hier, soll aber nun den eigentlichen Texten gelten.
Eine erste einfache Idee besteht darin, dass nicht ein zufälliges Wort verwendet wird, sondern ein Wort, welches im Text auf einen schon vorhandenen Begriff folgt. Als Beispiel sollen die beiden folgenden Sätze aus dem Klexikon (wieder zu Steinzeit) dienen:
Wie die Menschen in der Steinzeit lebten, müssen die Archäologen aufgrund von Funden herausfinden. Die Steinzeit ist der älteste Abschnitt in der Geschichte der Menschheit.
Während in diesem kurzen Text die meisten Wörter eindeutige nachfolgende Begriffe haben, gibt es für die beiden Artikel „die“ und „der“ mehre Möglichkeiten. Damit kann nun eine Liste mit folgender Struktur aufgebaut werden:
... > ... der > älteste, Menscheit die > Menschen, Steinzeit ... > ...
Ob dabei das „Die“ ebenfalls berücksichtig werden soll, hängt davon ab, wieweit die Texte in der Wortliste vereinfacht werden sollen.
Das Snap!-Beispiel stell für das Erzeugen einer entsprechenden Liste (Struktur) folgenden Block zu Verfügung:
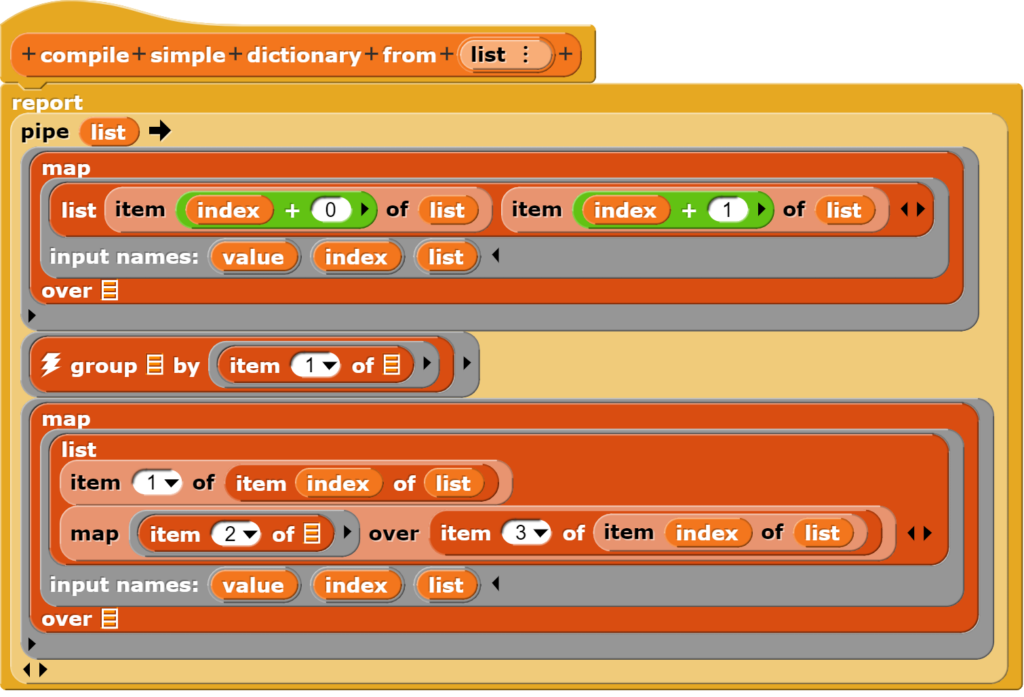
Das einfache Wörterbuch wird in mehreren Schritten erzeugt. Zuerst einmal werden alle Wörter mit ihren nachfolgenden Wörtern verknüpft. Anschliessend wird überprüft, ob es Wörter gibt, die mehrmals im Text vorkommen. Für diese wird dann ein gemeinsamer Eintrag mit allen nachfolgenden Wörtern erzeugt. Schliesslich wird die so gewonnene Listenstruktur noch einmal vereinheitlicht.
Für das Wort „ist“ sieht der entsprechende Listeneintrag beispielsweise so aus:

Wird nun dieses Wörterbuch für die Generierung von Texten verwendet, kann das Programm überall dort, wo mehrere Alternativen zu Verfügung stehen, eine Zufallsentscheidung treffen. Die dafür benötigten Blöcke sind:
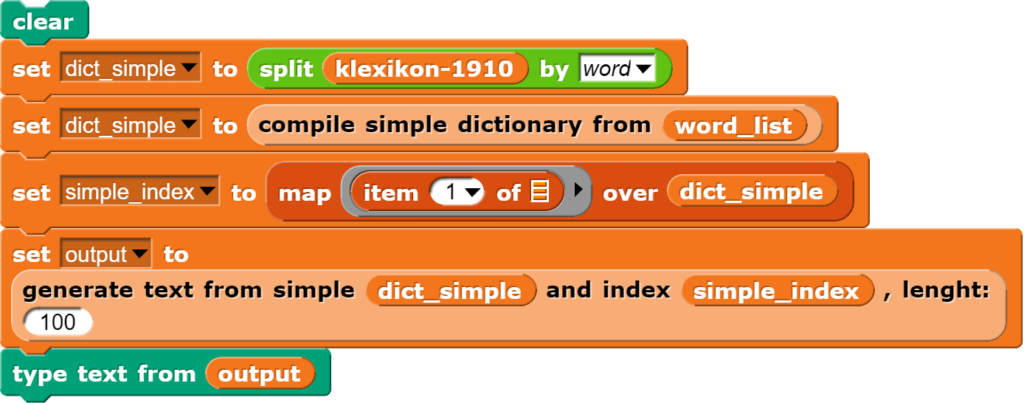
Die so erzeugten Texte täuschen einen höheren Zusammenhalt vor als wirklich vorhanden ist, denn aufgrund der überschaubaren Textmenge sind jeweils nicht besonders viele Entscheidungsalternativen vorhanden. Trotzdem sind viele Logikbrüche im Text zu erkennen.

Markow-Ketten
Der schwache Bezug zwischen einem gegebenen Begriff und dem nachfolgenden Wort (unter Umständen sehr viele Möglichkeiten) kann korrigiert werden, wenn an die Stelle des einen Suchbegriffes mehrere Wörter treten. Im vorliegenden Beispiel werden dafür Dreiergruppen von Wörtern als Schlüssel im Wörterbuch genutzt. Das entsprechende Wörterbuch wird mit einem leicht veränderten Block erzeugt.
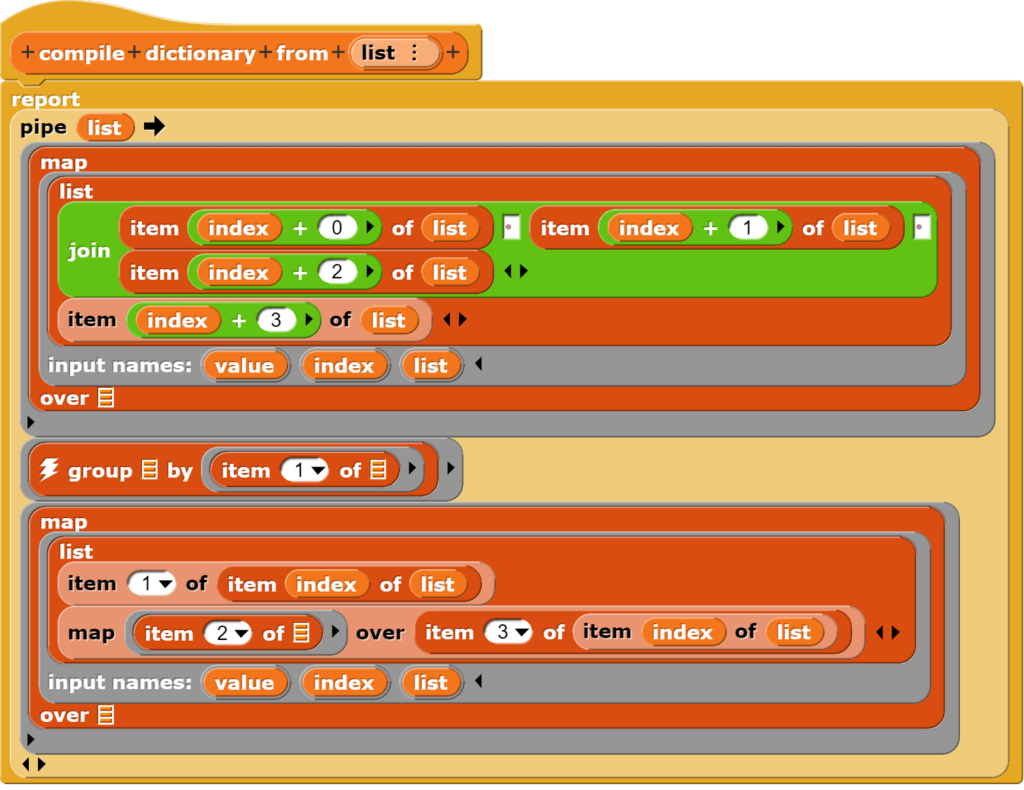
Die mithilfe der Markow-Ketten erzeugten Texte weisen nun einen grösseren inneren Zusammenhalt auf.

Nachdem nun an einem überschaubaren Text gezeigt wurde, dass die entsprechende Programmlogik funktioniert, ist es Zeit, einen grösseren Textkorpus zu verwenden.
Verwendung von Textkorpora
Während es noch vor wenigen Jahren äusserst schwierig war, insbesondere deutschsprachige Textkorpora zu finden, sind diese nun problemlos erhältlich. Eine gute Anlaufstelle ist beispielsweise der „Korpus einfaches Deutsch (KED)„. Dort findet man auch die Texte aus dem Klexikon. Da diese in der zum Herunterladen angebotenen ZIP-Datei als Einzeltexte vorliegen, führt man sie am besten via Kommandozeile zusammen. Unter Windows funktioniert dies mit folgendem Befehl:
type *.txt > klexikon.txt
Ob man anschliessend den Gesamttext noch von Interpunktionszeichen etc. säubert, muss man selbst entscheiden. Eine bereits überarbeitete Variante wird am Schluss dieses Beitrages zu Verfügung gestellt.
Um einen entsprechenden Text in Snap! zu verwenden, kann man diesen aus dem Dateimanager direkt in die Snap!-Umgebung hineinziehen. Anschliessend steht der Text als Variable zu Verfügung.
An dieser Stelle ist eine Warnung angebracht: Möchte man sein Werk in der Snap!-Cloud speichern, ist dabei zu beachten, dass Projekte nicht grösser als 10 MByte sein dürfen. Vor dem Speichern sollte man also die entsprechenden Daten wieder aus der Snap!-Datei löschen. Dazu stehen im Beispiel einige Blöcke zu Verfügung.
Versuch mit dem Gesamttext des Klexikons
Das Erzeugen des Wörterbuches aus dem Klexikon-Text funktioniert genau gleich wie oben beschrieben. Allerdings dauert dessen Generierung entsprechend länger. Auf einem einigermassen modernen Computer dauert die Berechnung zwischen ca. 5-10 Minuten.
Auch die Generierung der Text dauert etwas länger, weil bei der Suche nach den entsprechenden Wortfolgen ein umfangreicherer Datenbestand durchforstet werden muss. Für 100 Wörter muss man mit etwa 20 Sekunden Laufzeit rechnen.
Das Resultat dieser Bemühungen sieht dann beispielsweise so aus:

Die „enttäuschenden“ resultierenden Textbeispiele zeigen, ChatGPT nutzt weit raffiniertere Techniken als ein bloss auf Markow-Ketten aufbauendes Wörterbuch.
Einsatz im Unterricht
Die zu Verfügung gestellten Snap!-Blöcke eignen sich, um auf verschiedenen Abstraktionsstufen an das Thema heranzugehen. Insbesondere zeigen sie auch auf, dass sowohl unterschiedliche Herangehensweisen als auch verschiedene Ausgangsmaterialen zu qualitativ anderen Ergebnissen führen können.
Falls man sich fragt, weshalb der meist etwas ungewohnte funktionale Ansatz anstatt eines rein iterativen Vorgehens (z.B. mittels for-Schleife) verwendet wurde, ist die Antwort einfach: In Snap! sind funktionale Ansätze wesentlich performanter als die Verwendung von Schleifen.
Die Tatsache, dass die Generierung der Wörterbücher wesentlich mehr Zeit benötigt, als das Generieren von Einzeltexten, kann dazu verwendet werden, auf die Kosten beim Trainieren von Sprachmodellen aus entsprechenden Textquellen hinzuweisen.
Es lohnt sich sicherlich auf darauf hinzuweisen, dass durch den Einbezug grösserer Textkorpora – das Klexikonbeispiel umfasst etwa 1.6 Millionen Wörter – mit mehreren Milliarden Wörtern, der technische Aufwand noch einmal ungleich höher ausfällt, da derart umfangreiche Datenmengen nicht mehr einfach im Speicher des Computers bearbeitet werden können.
Ob und inwiefern es sinnvoll ist, auf die erweiterten Techniken von Anwendungen wie ChatGPT einzugehen (so erfolgt die Auswahl nachfolgender Wörter gezielter), muss wahrscheinlich zu einem späteren Zeitpunkt noch einmal überdacht werden. Das vorliegende Beispiel ist ein erster Schritt dahin.
Materialien zur Textgenerierung
Hier finden sich die Materialien zum vorgestellten Beispiel:
- Snap!-Programm: Markov Chains – Functional
- Bearbeiteter Text des Klexikons: Klexikon-Text (ohne Satzzeichen)