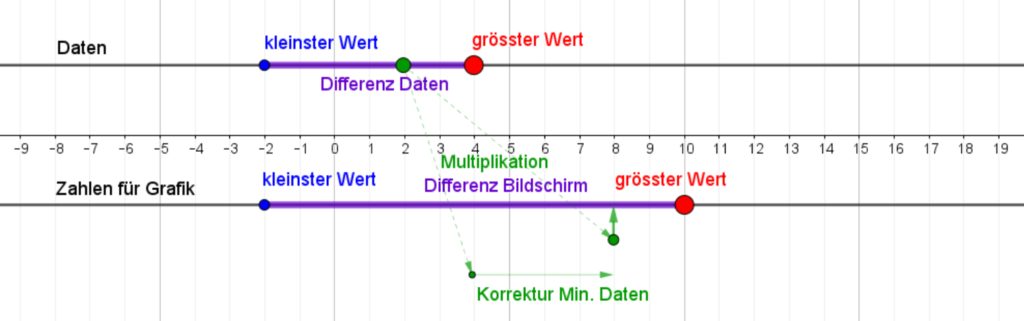
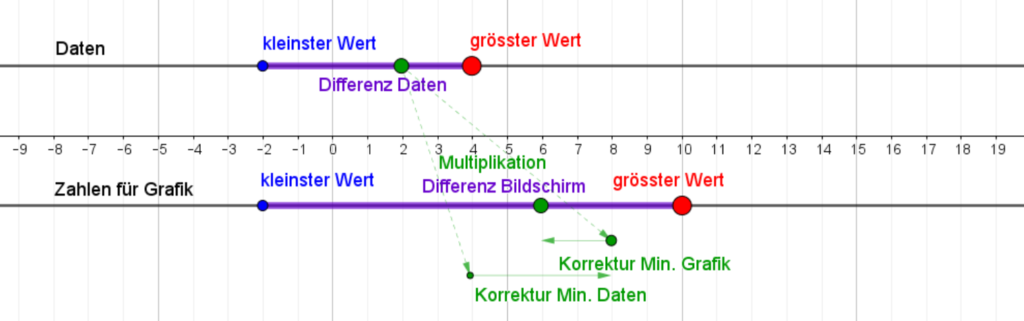
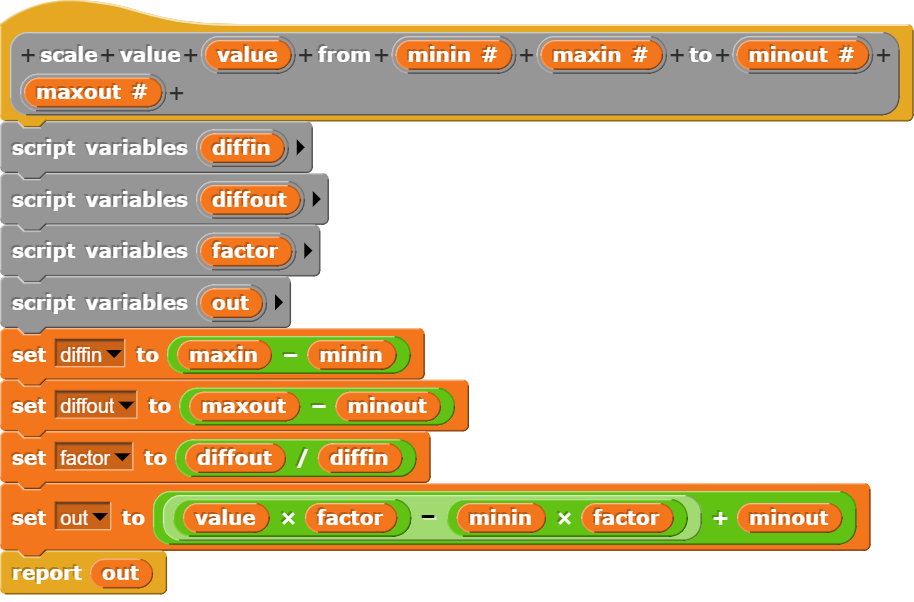
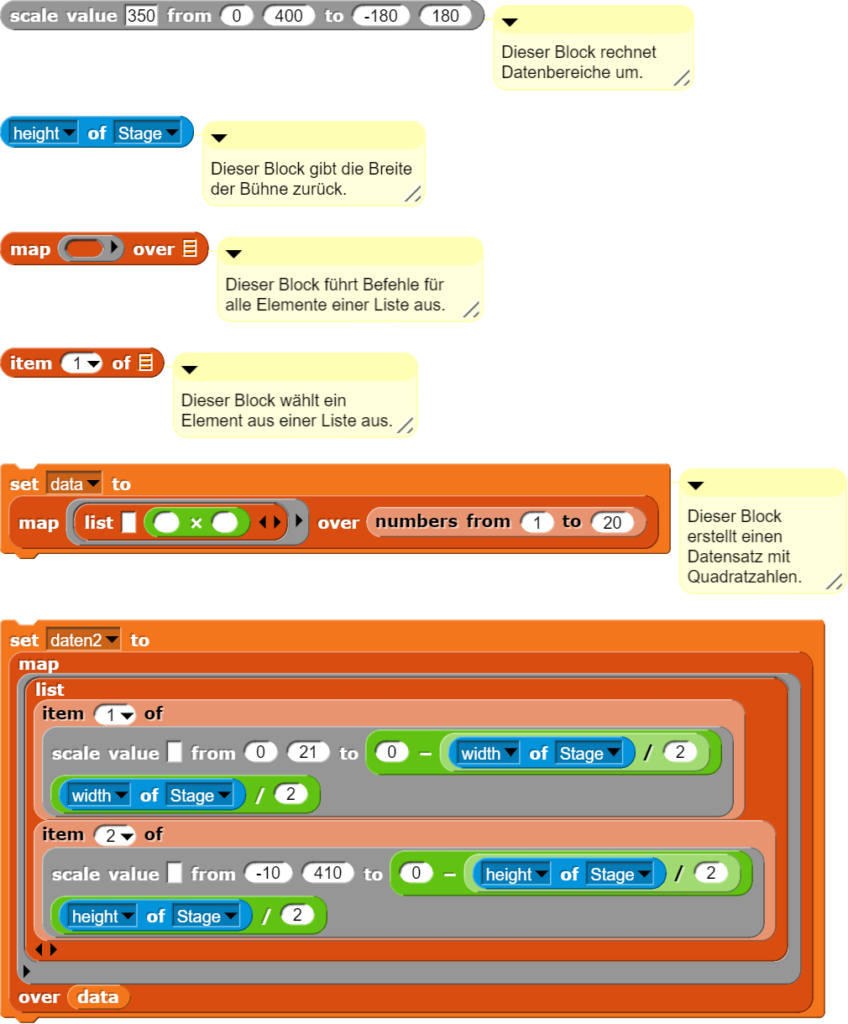
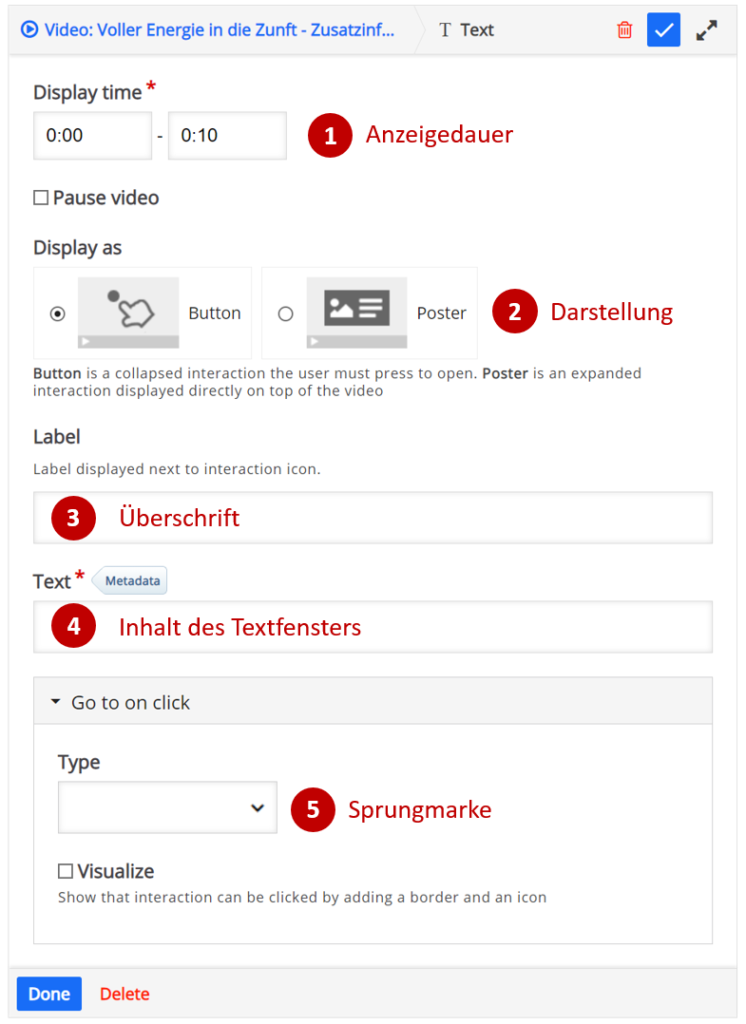
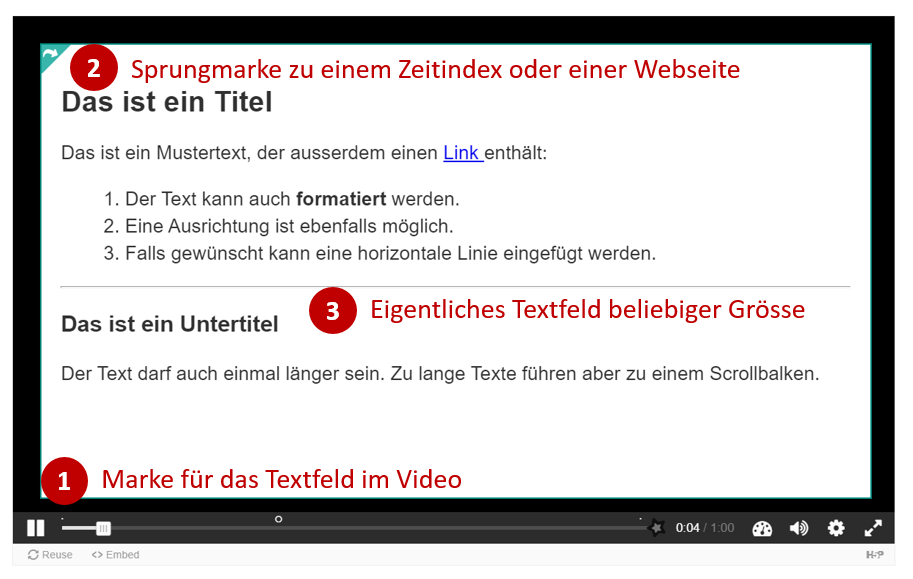
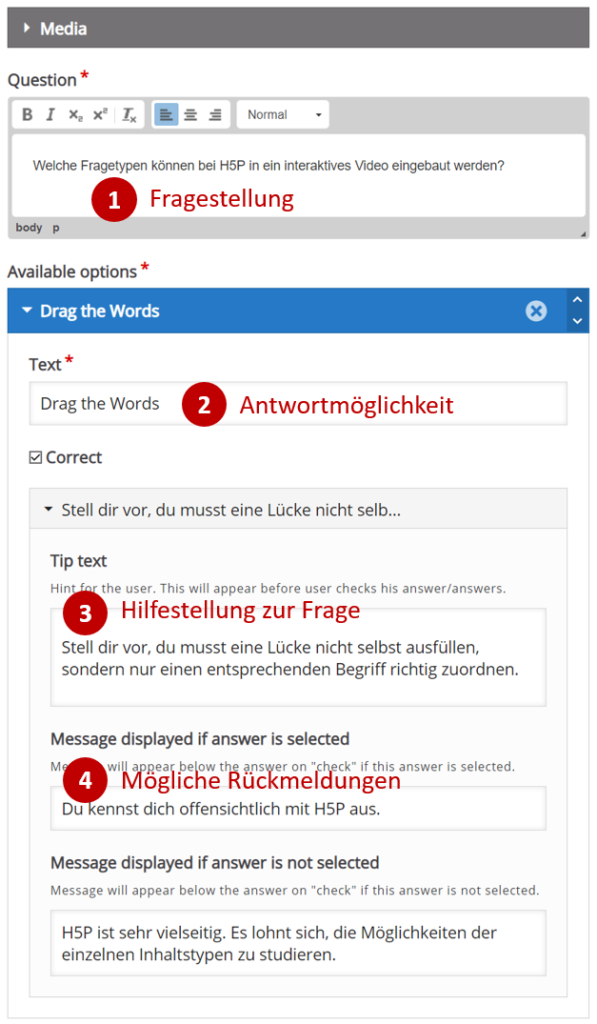
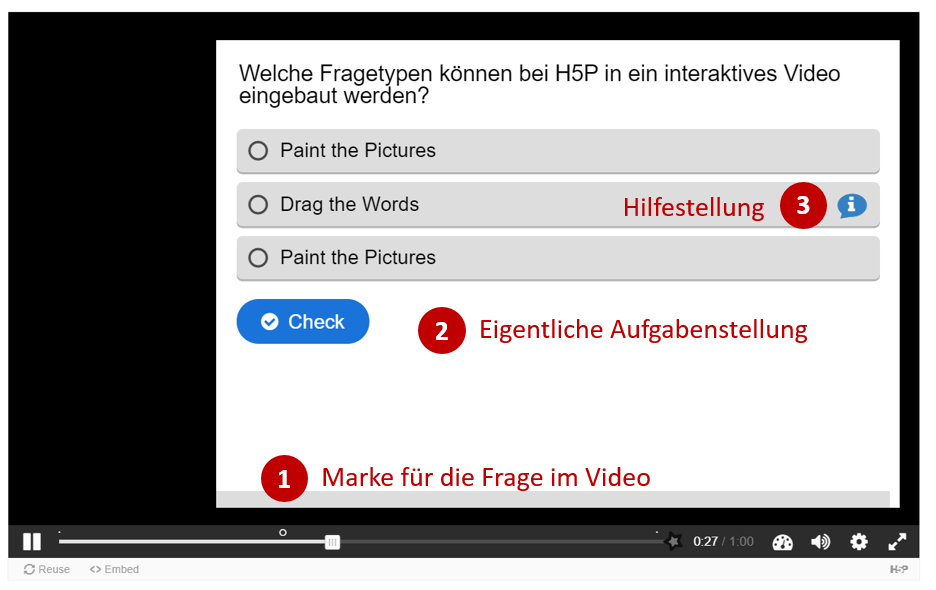
Die Auswertung von Daten gehört zu den Kernkompetenzen einer Gesellschaft, welche wissensbasiert handeln will. Deshalb erklärt auch der Lehrplan der Deutschschweiz das Auswerten von Daten aus der Umwelt der Schülerinnen und Schüler als eines der übergeordneten Ziele des Informatikunterrichts. Darauf hat unter anderem auch das Statistische Amt des Kantons Zürich reagiert und eine Webseite zum Thema Daten- & Statistikkompetenz aufgeschaltet, welche sich an Lernende wendet. Nebst theoretischen Überlegungen zur Wissenspyramide stellt das Amt auch einen Datensatz mit CO2-Daten zu Verfügung, der von den Lernenden analysiert werden kann. Diese Daten sollen dann mit der Statistiksoftware R und einem Beispielskript ausgewertet werden.
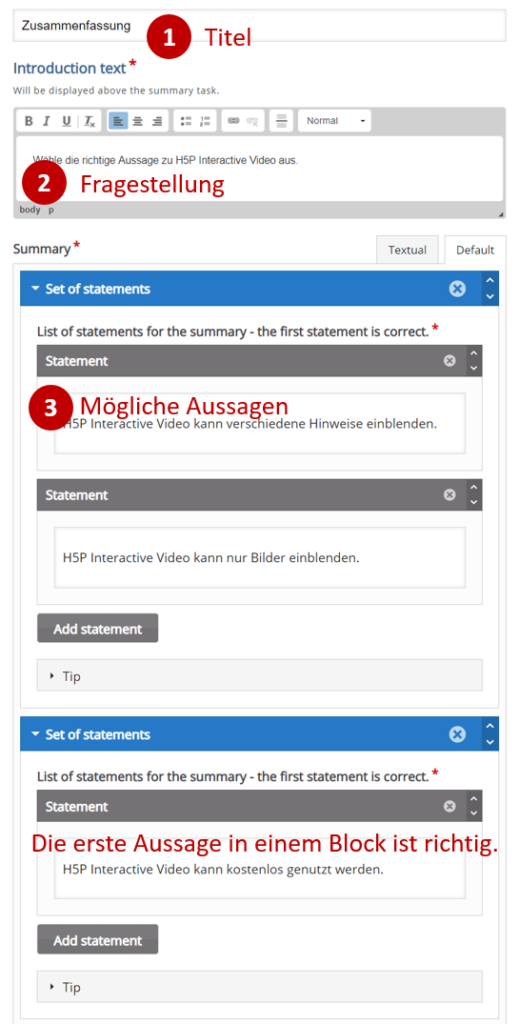
R für die Sekundarstufe I?
R ist ein sehr mächtiges, frei erhältliches und quelloffenes Statistikwerkzeug, welches durch zahlreiche Erweiterungen sich an die individuellen Bedürfnisse von Statistikerinnen und Statistikern anpassen lässt. Da es ausserdem über eine Skriptsprache gesteuert wird, lassen sich mit R durchgeführte statistische Analysen auch leicht nachvollziehen – vorausgesetzt, man kennt sich mit dem Werkzeug aus.
Diese Steuerung der Software über Textelemente führt aber auch dazu, dass viele Menschen sich mit R schwertun, da die Lernkurve ziemlich steil sein kann. Auf der Sekundarstufe I kommt hinzu, dass man nicht zwingend davon ausgehen kann, dass die Lernenden über genügende Fertigkeiten in Bezug auf das Tastaturschreiben verfügen, was die Hürde zusätzlich erhöhen kann. Nun ist es durchaus machbar, mit Schülerinnen und Schülern dieses Alters R zu verwenden, in der Regel bedarf dies aber viel Unterstützung durch die Lehrperson oder dann beschränkt sich die Auseinandersetzung auf eine relativ triviale Abarbeitung eines vorgefertigten Skripts mit geringer Wahrscheinlichkeit auf einen späteren Transfer. Ausserdem steht der Unterricht auf der Sekundarstufe I auch unter einem hohen Druck, die Lernenden dazu zu befähigen, die vielfältigen Kompetenzen des Lehrplans zu meistern und der Umgang von Daten ist nur einer von sieben Teilen im Bereich Medien und Informatik.
Rettung durch die Tabellenkalkulation?
Wäre es da nicht sinnvoll, auf eine bei den Schülerinnen und Schülern bekanntere und einfacher zu bedienende Software wie eine Tabellenkalkulation umzusteigen? Um eine Antwort auf diese Frage zu erhalten, müssen verschiedene Aspekte berücksichtigt werden:
- Der Datensatz selbst: Bei einfach aufgebauten oder kleinen Datensätzen mag eine Tabellenkalkulation die erste Wahl sein. Der CO2-Datensatz enthält aber über 2000 Datensätze, was einer Bearbeitung in einer Tabellenkalkulation nicht gerade entgegenkommt. Bei solch grossen Datensätzen ist es schwierig, den Überblick zu behalten.
- Das Ziel der Auswertung: Wenn es darum geht, schnell eine Summe zu berechnen oder eine Linien- oder Balkengrafik zu zeichnen, dass ist die Tabellenkalkulation meist die erste Wahl. Wenn aber umfassendere Untersuchungen durchgeführt werden sollen, kann es schwierig sein, die einzelnen Schritte im Prozess nachzuvollziehen und auf eine andere Datenlage anzuwenden. Und genau dies soll ja eines der Ziele der Arbeit mit dem CO2-Datensatz sein. Es geht nicht nur darum, Erkenntnisse über diesen einzelnen Datensatz zu gewinnen, sondern diese Kenntnisse später auch auf andere Daten anzuwenden, bei denen vielleicht eine ganz andere Fragestellung im Fokus steht.
- Die Methodik: In der Mathematik, Informatik und den Naturwissenschaften ist es üblich, mit Werkzeugen zu arbeiten, bei denen Arbeitsschritte nachvollziehbar sind. Eine Reihe von abzuarbeitenden Befehlen erfüllt diese Aufgabe in der Regel besser, als wenn man auf eine grafische Oberfläche setzt, wie dies bei der typischen Tabellenkalkulation der Fall ist. Die schlechte Nachvollziehbarkeit von Analysen mit Tabellenkalkulationen führt dann auch immer wieder zu Problemen. Dass dabei ein Produkt besonders häufig genannt wird, hat weniger mit dessen Qualität als vielmehr dessen grosser Verbreitung zu tun.
Diese Überlegungen zeigen, dass anscheinend nur die Wahl zwischen der unzugänglichen Arbeit mit einer Skriptsprache wie R oder der in den Naturwissenschaften eher weniger gern gesehenen, weil schlecht reproduzierbaren Arbeit mit einer Tabellenkalkulation bleibt.
Zu erreichende Ziele
In ein solches Dilemma verstrickt, lohnt es, sich noch einmal die Zielsetzungen vor Augen zu führen. Was sollen die Lernenden aus der Auseinandersetzung mit dem Lernobjekt (hier ein für Schulverhältnisse vergleichsweise grosser Datensatz) mitnehmen?
- Die Lernenden sollen eine grundsätzliche Fertigkeit im Umgang mit grösseren Datenmengen erwerben. Dazu gehören unter anderem:
Sich einen Überblick und die Inhalte des Datensatzes zu verschaffen;
einfache statistische Berechnungen auf den Datensatz anzuwenden;
den Datensatz möglicherweise visuell auszuwerten (wird in diesem Beitrag nicht behandelt); - Die Lernenden sollen dabei Methoden kennenlernen, welche typisch für das entsprechende professionelle Umfeld sind. Dazu gehören:
Die Arbeitsweise mit einer professionellen Statistiksoftware zumindest in Ansätzen kennen lernen;
bei der Arbeit mit Daten auf die Reproduzierbarkeit der Berechnungen zu achten;
Einblick in die Funktionsweise statistischer Methoden erlangen.
Grundsätzlich würde R diese Bedingungen erfüllen, den Anwender wird der Einstieg durch die neu zu erlernenden Konzepte mit der gleichzeitig abverlangten Genauigkeit beim Eingeben der Befehle (Tippfehler) aber erschwert. Eine didaktische Reduzierung auf den eigentlichen Kern, die Nutzung von flexiblen, reproduzierbaren Befehlen zum Umgang mit Daten ist also angesagt.
In den folgenden Ausführungen soll nun gezeigt werden, dass eine Sprache wie Snap! aufgrund der blockbasierten Schnittstelle dazu ideale Voraussetzungen bietet und damit den Lernenden einen späteren Umstieg auf ein Statistikprogramm wie R wesentlich erleichtern kann.
Umsetzung mit Snap!
Da Snap! es ermöglicht, eigene Blöcke (Funktionen, Befehle, …) zu schreiben, kann die benötigte Funktionalität den Lernenden entweder zu Verfügung gestellt werden, oder, falls dies erwünscht ist, können diese die Erweiterungen selbst schreiben oder zumindest deren Funktionsweise nachvollziehen.
Während Snap! schon von Grund auf viele interessante Blöcke enthält und diese durch bereits vorhandene Bibliotheken (z.B. Frequency Distribution Analysis, Variadic reporters) ergänzt werden können, ist zumindest bei einer ersten Auseinandersetzung mit grösseren Daten sinnvoll, den Lernenden entsprechend zugeschnittene Blöcke zu Verfügung zu stellen.
Deshalb ist es sinnvoll, einmal einen Blick in den entsprechenden Auftrag zum CO2-Datensatz zu werfen (siehe R Skript). Die Lernenden sollen …
- die Grösse des Datensatzes bestimmen (Anzahl Spalten und Zeilen);
- die Überschriften der einzelnen Spalten herauslesen;
- die Zeitabstände zwischen den Messzeitpunkten berechnen;
- den Mittelwert (mean), Zentralwert (median) und häufigst vorkommenden Wert (modus) bestimmen;
- Minimum und Maximum, sowie die Spannweite feststellen;
- die Standardabweichung (standard deviation) und Streuung (variance) berechnen;
- eine Übersichtstabelle (summary) zu den Daten generieren.
Nachdem die Aufgabenstellungen klar sind, können die entsprechenden Befehle zu Verfügung gestellt werden.
Didaktische Überlegungen
Bei der Umsetzung der entsprechenden Blöcke stellten sich erneut verschiedene Fragen:
- Soll sich die Bezeichnung der Blöcke an diejenige der Skriptsprache R anlehnen?
- Welchen Abstraktionsgrad sollen die einzelnen Blöcke aufweisen?
- Wie fehlertolerant sollen die Eingabemöglichkeiten zu den Blöcken gestaltet werden?
- Im Zweifelsfalle: Soll der Fokus beim Schreiben von Blöcken auf die Effizienz oder Nachvollziehbarkeit gelegt werden?
Die Beantwortung dieser Fragen führt unweigerlich zu entsprechenden Designentscheidungen. Grundsätzlich können diese aber später korrigiert werden, zumindest dann, wenn nur die Namen einzelner Blöcke und deren Programmierung angepasst werden, nicht aber deren Schnittstelle gegen aussen geändert wird. Bereits hier zeigt es sich, dass auch vergleichsweise triviale Aufgabenstellungen in Snap! sehr schnell zu Fragen führen, die über das eigentliche Programmieren hinausgehen und eigentliche Aufgaben der Informatik sind.
Für die konkrete Umsetzung wurden die Fragestellungen wie folgt beantwortet:
- Eine Übernahme der genauen Bezeichnungen von R wurde als nicht erstrebenswert angesehen, da es darum geht, die Prinzipien zu verstehen. Ansonsten hätte man auch einfach das vorhandene Skript abarbeiten können. Die Lernenden sollen die Grundprinzipien erlernen, nicht eine ganz bestimmte Umsetzung in einer Sprache wie R.
- Die Blöcke dürfen einen unterschiedlichen Abstraktionsgrad aufweisen, d.h., die Lernenden sollen bei Bedarf auch Blöcke mit einem tieferen Abstraktionsgrad nutzen können. Zudem ist es in Snap! bei den meisten (bei allen selbstgeschriebenen) Blöcken möglich, die entsprechende Programmierung einzusehen.
- Die Fehlertoleranz der einzelnen Blöcke ist momentan auf unterschiedlichem Niveau (aus Zeitgründen) und soll deshalb erst einmal dokumentiert werden. Diese kann aber später bei Bedarf nachgerüstet werden. Didaktisch kann es sinnvoll sein, mit den Lernenden darüber zu sprechen, weshalb einige Blöcke weniger fehlertolerant sind als andere und was notwendig ist, um eine solche Fehlertoleranz zu erzielen.
- Beim Schreiben der Blöcke wurde der Fokus auf die Nachvollziehbarkeit gelegt, wobei häufig Prinzipien genutzt werden, die typischerweise auch bei R zu finden sind.
Blöcke zum Filtern von Daten
Die meisten Blöcke wurden so umgesetzt, dass sie mit dem ganzen Datensatz (inklusive Spaltenüberschriften) funktionieren. Für die bessere Nachvollziehbarkeit werden die Blöcke inklusive der entsprechenden Programmierung vorgestellt
Namen der Spaltenüberschriften bestimmen
Mit diesem Block wird die Zeile 1 der CSV-Tabelle ausgelesen und als Liste zurückgegeben. Die Programmierung zeigt, dass dafür eigentlich kein eigener Block notwendig ist, denn er verpackt nur bereits vorhandene Funktionalität und macht sie damit etwas benutzerfreundlicher.

Anzahl der Zeilen und Spalten bestimmen
Zeilen und Spalten unterscheiden sich in einer Tabelle in Snap! konzeptionell, weshalb der Zugriff jeweils anders erfolgt. Um die Zahl der Spalten zu erhalten, geht man gleich vor. wie im oberen Beispiel geschildert. Nur bestimmt man zusätzlich noch, wie lang die zurückgegebene Liste ist.
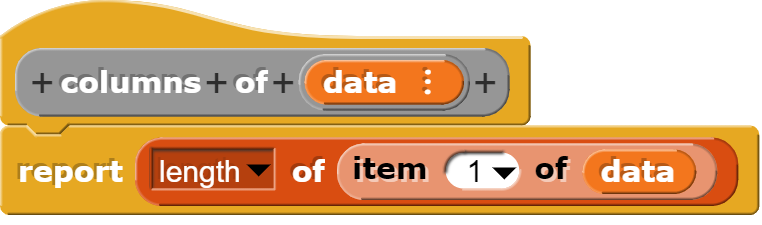
Der Befehl für die Zahl der Zeilen einer Tabelle, verpackt wieder nur einen schon bestehenden Block.
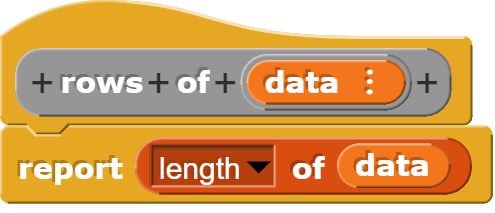
Wenn man ganz auf selbstgeschriebene Blöcke verzichten möchte, kann man auch einen bereits vorhandenen Block in Snap verwenden:

Dieser Block liefert die Dimensionen einer Tabelle als Liste der Form (Zeilenzahl, Spaltenzahl) zurück.
Nummer einer Spalte mit einer bestimmten Überschrift
Dieser Block dient nur dem Komfort. Anstatt eine Spalte über ihre Nummer zu adressieren, geht dies auch mit der Spaltenüberschrift.

Hier wurde aufgrund der einfachen Programmierung darauf verzichtet, auf den schon bestehenden Block „names of colums of“ zurückzugreifen.
Eine Datenzeile auslesen
Bei diesem Block handelt es sich um eine Verallgemeinerung des Blockes zum Auslesen der Spaltenüberschriften. Damit können die Werte einer beliebigen Zeile ausgelesen werden.
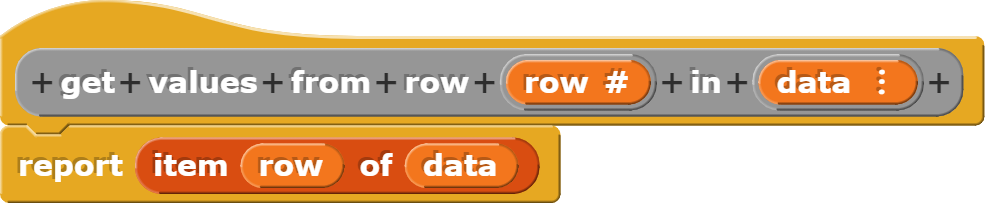
Eine Spalte auslesen
Da Snap! Tabellen als Listen von Listen darstellt, ist das Auslesen der Werte in einer Spalte etwas komplizierter als bei einer Zeile. Die ersten drei Zeilen des Datensatzes werden bei Snap! so repräsentiert:
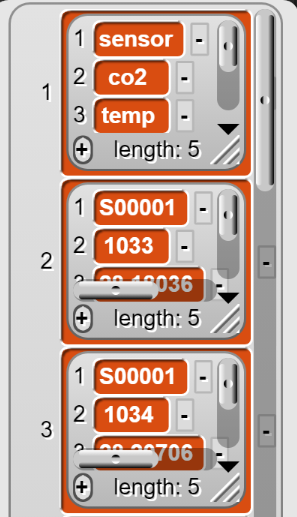
Aus diesem Grund muss aus jeder Liste (eine Zeile der Daten) jeweils der entsprechende Wert ausgelesen und anschliessend in eine neue Liste geschrieben werden. Dies geschieht mithilfe des map-Blockes.

Der map-Block führt einen Befehl über alle Elemente einer Liste aus und ist ein sehr wichtiges Werkzeug, welches auch in R zu Verfügung steht. Dort bei Nutzenden, welche R nicht gut kennen, aber gerne durch eine wesentlich ineffizientere for-Schleife ersetzt wird. Fall die Zeit vorhanden ist, lohnt es sich, mit den Lernenden den map-Block eingehender zu behandeln, da damit in vielen Fällen das Konzept der for-Schleife zu Seite gelegt werden kann.
Grundsätzlich gilt in Snap!: Wenn möglich sollte man eine For-Schlaufe durch einen forEach-Block ersetzen und diesen gegebenenfalls wiederum durch einen map-Block. Dabei verliert man unter Umständen etwas Flexibilität, die Programmierung wird aber eleganter und vor allem werden die Befehle schnell ausgeführt.
Einen Datenbereich auslesen
Manchmal möchte man statt nur einer Zeile oder einer Spalte einen Datenbereich auslesen. Bei sehr grossen Datensätzen wendet man beispielsweise beim Schreiben eines Skriptes die Befehle nur auf einen Teil des Datensatzes an, weil sonst die Berechnungen zu lange dauern. Ist man sich sicher, dass das eigene Programm funktioniert, lässt man es über den ganzen Datensatz laufen.
Einen Ausschnitt aus den Daten zu erhalten, funktioniert auch mit einer Abfolge von Befehlen, einfacher geht es aber mit folgendem Block:
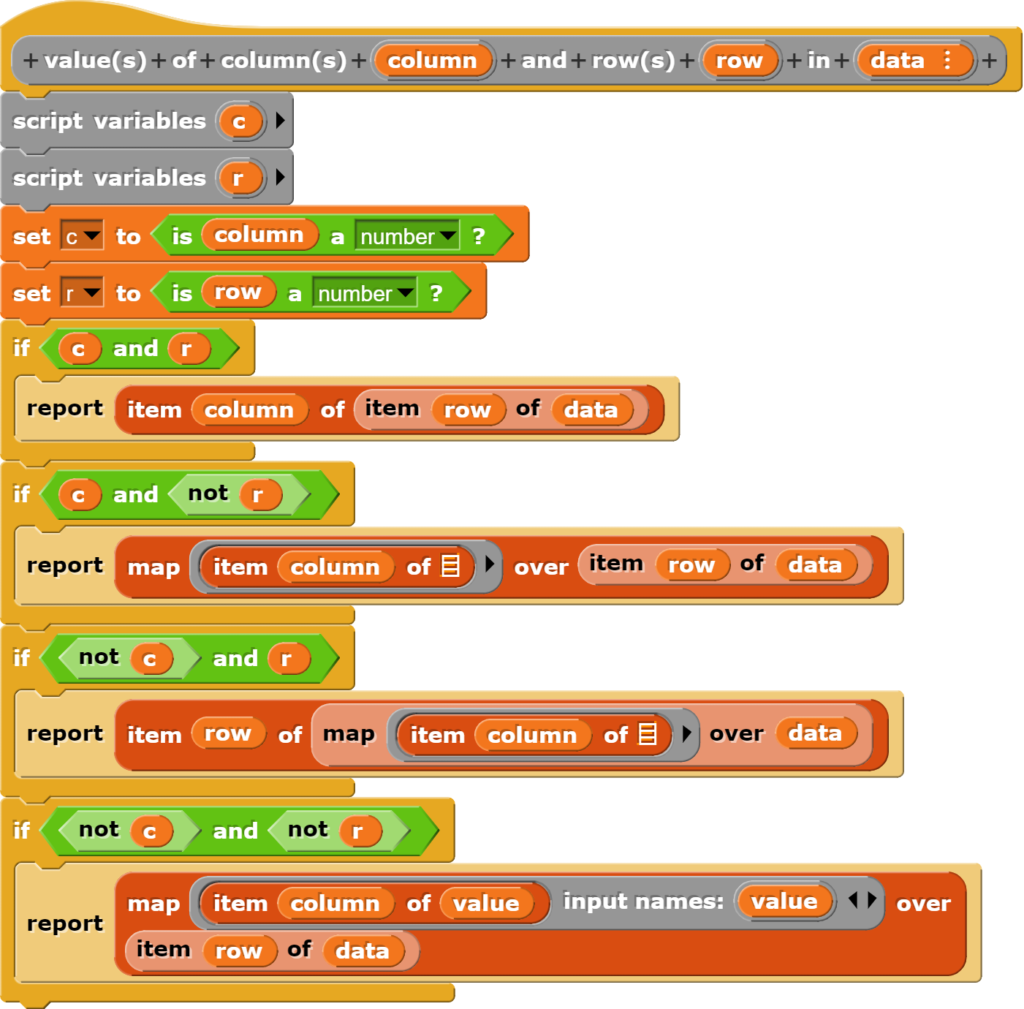
Nebst dem map-Befehl enthält dieser Block noch die Besonderheit, dass er bei der Eingabe für die Zeile und Spalte sowohl eine Zahl als auch eine Liste entgegennimmt, was normalerweise nicht ohne Weiteres möglich ist. Dazu prüft der Block, ob es sich bei der Eingabe um eine Zahl handelt und verzweigt dann dementsprechend in einen anderen Zweig der Programmierung. Damit versteckt der Block eine technische Schwierigkeit bei der Programmierung mit Snap! vor den Lernenden. Umgesetzt wurde dieser Ansatz hier, weil für Spezialfälle nicht noch eigene Blöcke geschrieben werden sollten.
Tabelle drehen
Manchmal ist es sinnvoll, eine Tabelle um 90° zu drehen, weil dadurch die Auswertung der Daten erleichtert wird.

Ein Beispiel soll zeigen, was damit gemeint ist. In Snap! wird die CO2-Tabelle so dargestellt:
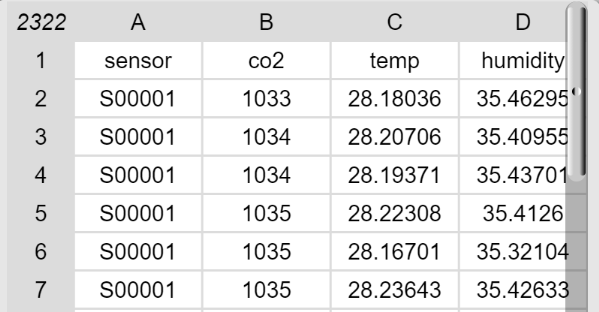
Wenn diese um 90° gedreht wird, präsentiert sich die Tabelle so:
Die Zeilen sind zu Spalten geworden und umgekehrt. Die mit verschachtelten map-Blöcken umgesetzte Funktionalität kann man seit einiger Zeit auch mit einem vorgegebenen Block noch einfacher umgesetzt werden:

Zusammenführen von Datensätzen
Der erwähnten Block „columns of“ kann auch dazu verwendet werden, zwei Tabellen mit wenigen Zeilen Code zusammenzuführen.

Dabei werden die Daten wieder zuerst gedreht, aneinandergehängt und schliesslich wieder zurückgedreht. Das funktioniert wesentlich einfacher als mit der Verwendung einer expliziten Schlaufe.
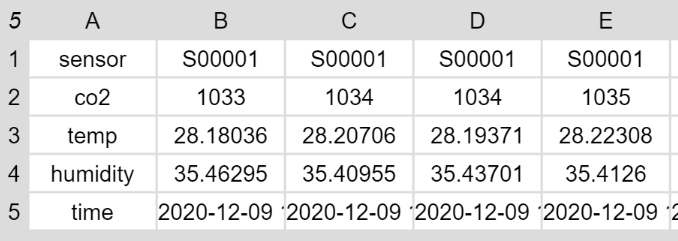
Löschen von Spalten in einer Tabelle
Um eine Spalte in einer Tabelle zu löschen, wird diese unter Verwendung aller Spalten, die nicht gelöscht werden sollen, neu geschrieben. Damit dies einigermassen komfortable funktioniert, wird zuerst eine Hilfsfunktion benötigt, welche eine Liste der Spalten generiert, die behalten werden sollen.
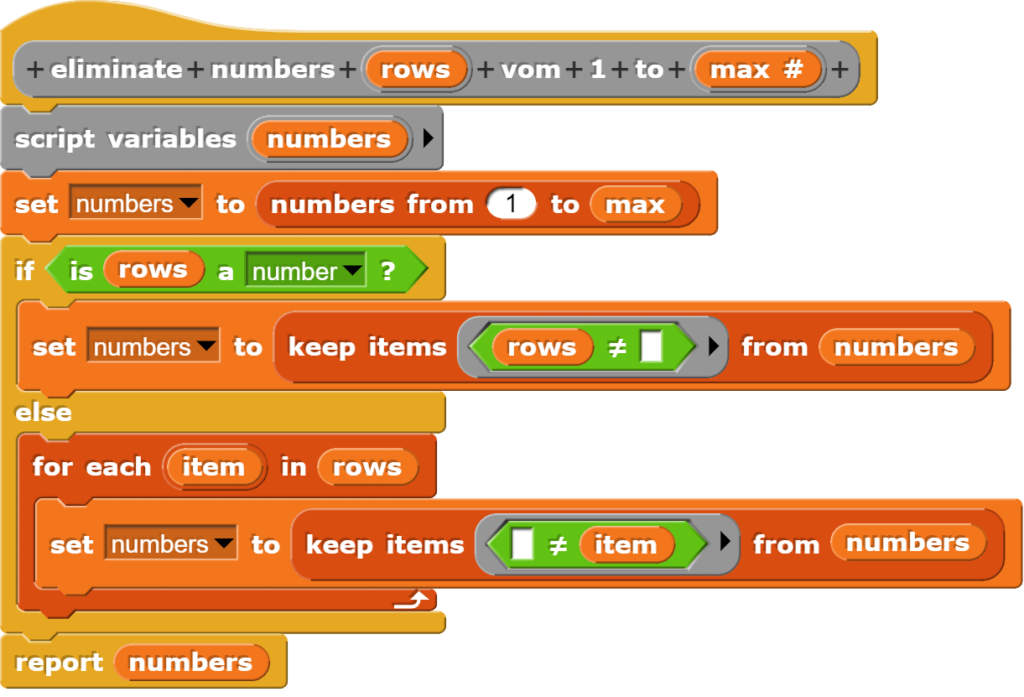
Dank der Fallunterscheidung funktioniert dies mit einzelnen Zahlen und Listen von Zahlen.

Der Block schreibt also die Tabelle neu und verwendet dabei alle Spalter, ausser derjenigen, die eben gelöscht werden soll.
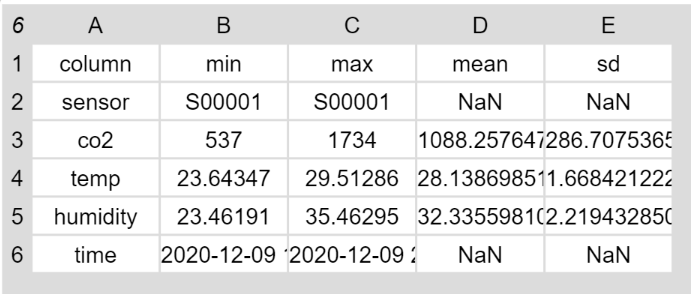
Zusammenfassung der Tabellendaten
Der Block zur Zusammenfassung der Tabellendaten weist einen wesentlich höheren Abstraktionsgrad auf und greift dabei auf verschiedene bereits vorhandene und zusätzlich geschriebene Blöcke zurück.
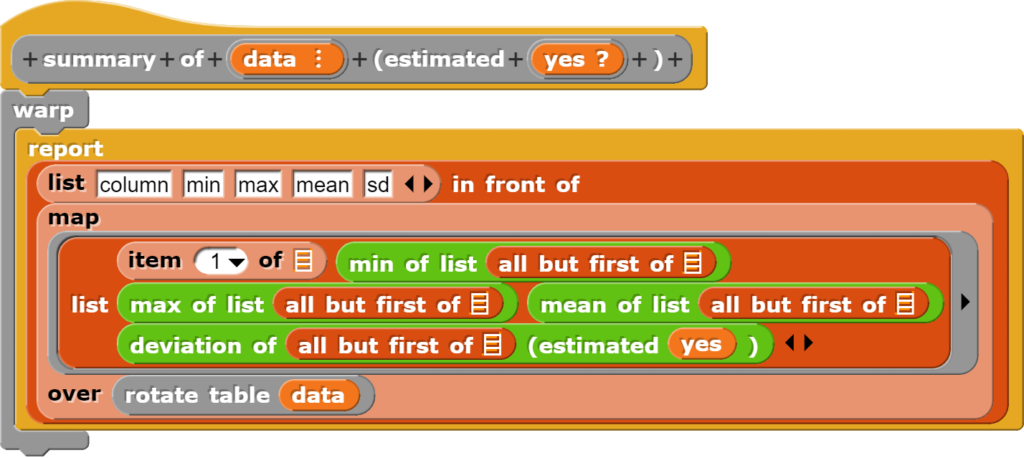
Grundsätzlich erzeugt der Block eine neue Tabelle mit den Überschriften „column“, „min“, „max“, „mean“ und „sd“. Die eigentliche Tabelle wird erzeugt, indem für jede Spalte die entsprechenden Werte berechnet werden, wobei die Tabelle zur einfacheren Berechnung noch rotiert wird.
Blöcke zur Berechnung statistischer Kennwerte
Im nächsten Abschnitt werden Blöcke vorgestellt, die zur Berechnung statistischer Kennwerte verwendet werden können. Damit diese funktionierten, dürfen die zugrundeliegenden Listen in der Regel nur Zahlen enthalten.
Minimum, Maximum und Spannweite
Die Blöcke zur Berechnung des Minimums und Maximums sortieren die Daten zuerst und holen sich dann den ersten, respektive letzten Wert aus der sortierten Liste.
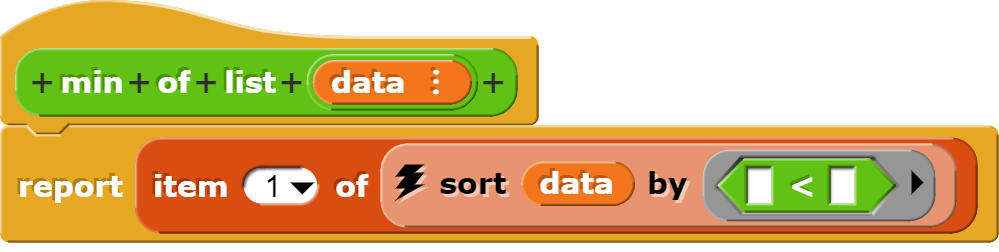
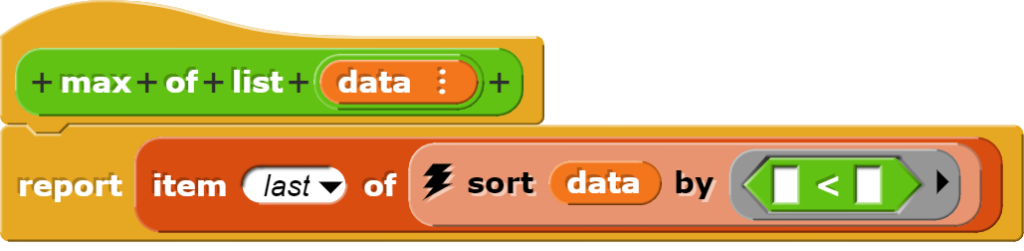
Natürlich hätte man den max-Block auch so programmieren können, dass man mit dem „grösser als“-Zeichen operiert.
Der Block zur Berechnung der Spannweite ruft einfach „max“ und „min“ auf und berechnet dann die Differenz.
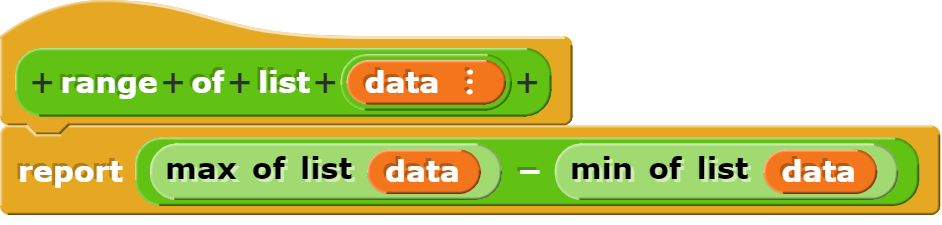
Bei der Programmierung dieses Blocks wurde bewusst auf eine Optimierung (die Liste wird zweimal sortiert) verzichtet, damit klarer wird, dass die Spannweite die Differenz von Maximum und Minimum ist. Wenn mit sehr grossen Datensätzen gearbeitet wird, kann es sinnvoll sein, eine optimierte Version zu verwenden. Diese könnte dann so aussehen:
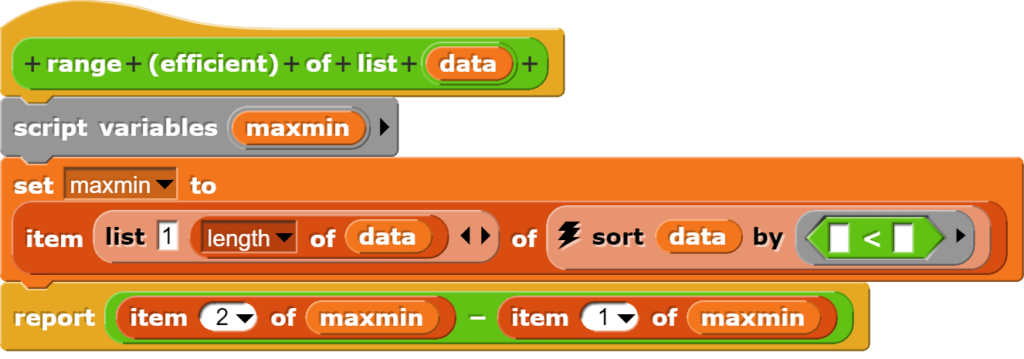
Da bei ca. 2000 Werten die Berechnungszeit auch bei einem langsameren Computer unter einer Sekunde liegen dürfte, lohnt sich eine solche Anpassung im Schulgebrauch wahrscheinlich nicht.
Anzahl unterschiedlicher Werte
Manchmal ist es praktisch, wenn man weiss, wie viele unterschiedliche Werte sich in einer Spalte einer Tabelle befinden. Programmtechnisch lässt sich dies in Snap! einfach umsetzen.

Zuerst wird die Liste auf die unterschiedlichen Werte reduziert, anschliessend wird noch die Länge dieser reduzierten Liste abgefragt.
Sinnvoll ist die Anwendung eines solchen Befehls vor allem bei Listen, deren Inhalte nicht aus Zahlen bestehen. Will man den Befehl trotzdem mit Zahlen verwenden, kann man diese beispielsweise runden, um deren Vielfalt zu reduzieren.
Mittelwert, Zentralwert und häufigster Wert
Die Ausführungen zu den drei statistischen Werten (mean, median, modus) sollen sich hier auf die Umsetzung als Snap!-Blöcke beschränken. Am einfachsten ist es, das arithmetische Mittel (mean) zu berechnen.

Programmtechnisch wird die Summe aller Werte gebildet, dabei hilft der entsprechende Summenbefehl aus der Bibliothek „Variadic Reporters“, die anschliessend durch die Anzahl der Werte dividiert wird.
Komplizierter ist die Berechnung des Zentralwerts, weil dazu die Liste sortiert und ausserdem eine Fallunterscheidung (gerade oder ungerade Anzahl von Werten) vorgenommen werden muss.
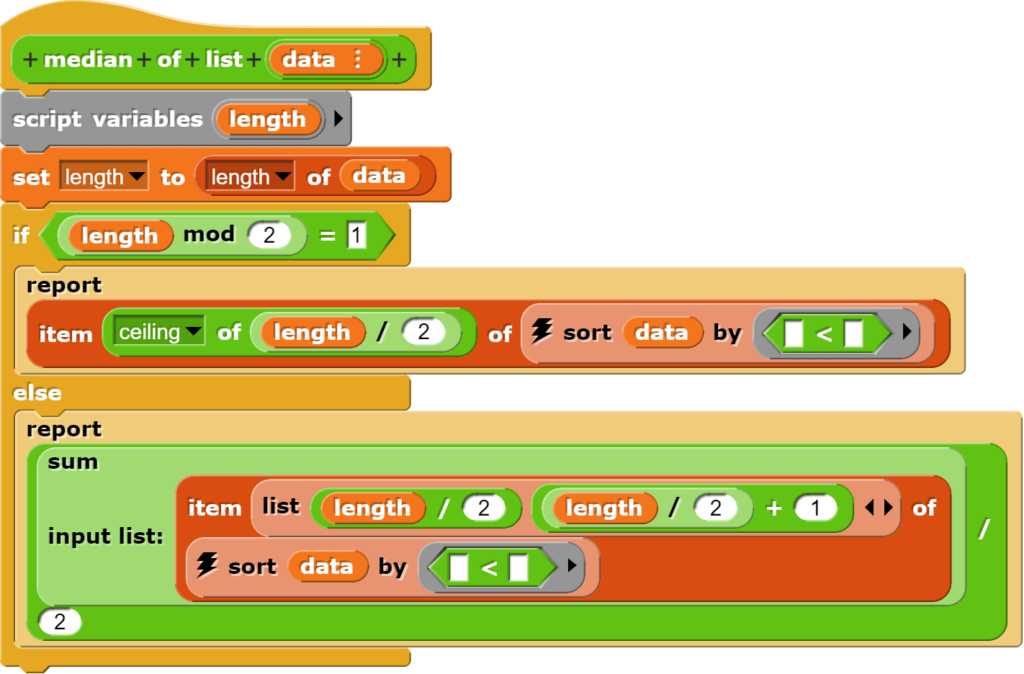
Zuerst wird mit dem Modulus-Operator geprüft, ob die Anzahl der Werte ungerade ist. Wenn dem so ist, wird die Mitte der Liste bestimmt und der entsprechende Wert zurückgegeben. Handelt es sich um eine gerade Anzahl von Werten, wird aus den beiden Werten in der Mitte das arithmetische Mittel berechnet. Dabei wurde auf einen Einsatz des schon bestehenden Blockes zur Berechnung des arithmetischen Mittels verzichtet, weil die Division mit Zwei in diesem Fall wohl anschaulicher ist.
Am kompliziertesten ist die Berechnung des häufigsten Wertes, auch wenn dies aus der Anzahl der Blockbefehle nicht unmittelbar ersichtlich ist.

Die scheinbar nur aus einem Schritt bestehende Programmierung führt folgende Schritte durch: Zuerst werden die Daten mit „analyze“ in Gruppen aufgeteilt und gezählt, aus wie vielen Elementen jeder dieser Gruppe besteht. Anschliessend wird die so berechnete Liste nach der Anzahl der Mitglieder sortiert und ganz zuletzt wird der höchste Wert für eine Anzahl von Elementen zurückgeliefert. Falls es mehrere Höchstwerte mit der gleichen Anzahl von Elementen gibt, wird dies in der Programmierung nicht berücksichtigt. Der Block gibt immer nur einen Wert zurück.
Standardabweichung und Streuung
Die Standardabweichung (standard deviation) und die Streuung (variance) sind beide statistische Kennwerte, die angeben, wie sehr sich die Daten in einem Datensatz voneinander unterscheiden. Bei beiden Werten gibt es jeweils zwei Rechenverfahren, die abhängig davon sind, ob man eine ganze Population oder nur eine Auswahl davon erfasst hat. Auch hier sollen sich die Ausführungen auf die Programmierung beschränken.
Die Varianz berechnet sich als der Durchschnitt der Quadrate der Abweichungen zum Mittelwert der Daten.
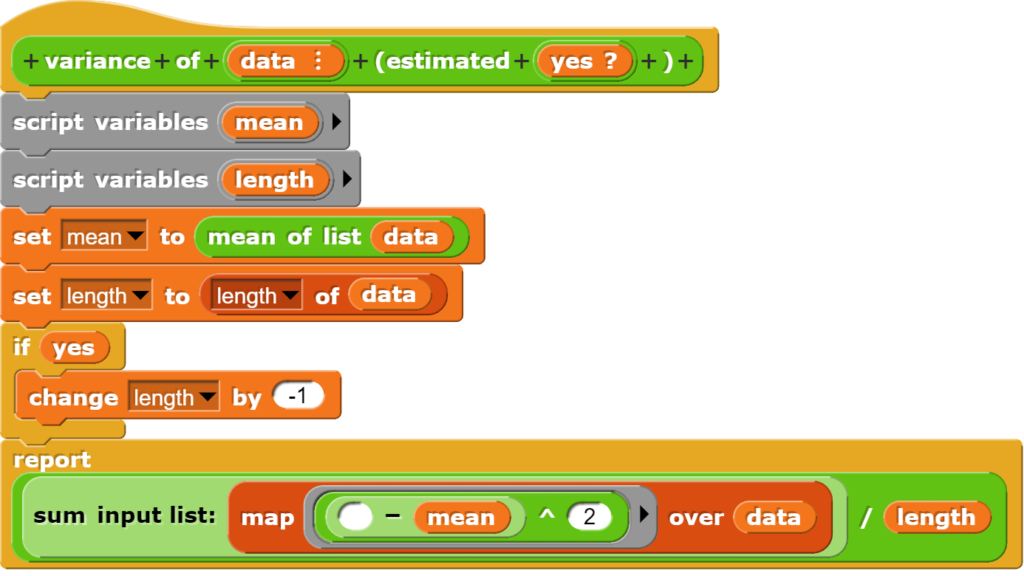
Zuerst wird das arithmetische Mittel berechnet, dann wird für jeden Wert die Abweichung vom Mittelwert quadriert und anschliessend die aufsummierten Quadrate durch die Anzahl der Werte (oder Werte -1) dividiert. Bei der Fallunterscheidung wurde nur der Wert für die Anzahl der Listenelemente angepasst, damit im Programmcode weniger von der eigentlichen Berechnung der Werte abgelenkt wird.
Die Standardabweichung kann nur einfach als Quadratwurzel der Streuung berechnet werden.
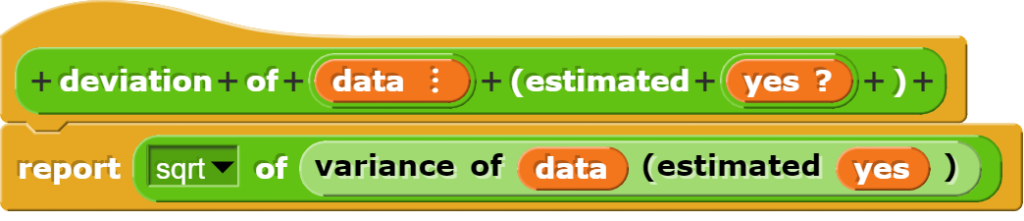
Umgang mit Zeitangaben
Zeitangaben am Computer sind ein kompliziertes Problem ,weil die verschiedenen Umrechnungen, z.B. 60 s = 1 min oder 24 h = 1 d, berücksichtigt werden müssen. Ausserdem gibt es dann noch die Schaltjahre usw. Aus diesem Grund werden Zeitangaben am Computer meist auf Sekunden (oder Millisekunden) umgerechnet, welche seit einem bestimmten Zeitpunkt (beispielsweise dem 1.1.1970) vergangen sind. Bei der Programmierung der entsprechenden Zeitfunktionalität für Snap! wurde ein ähnlicher Ansatz verfolgt. (Es ist natürlich auch möglich, entsprechende Befehle mit einem JavaScript-Block einzufügen, aber das widerspräche dem Versuch, den Lernenden die Grundlagen der Informatik zu vermitteln).
Damit am Schluss die Berechnung der Unterschiede zwischen zwei Zeitangaben einigermassen benutzerfreundlich erfolgen kann, wird zuerst eine Hilfsfunktion definiert, welche den Zeitunterschied zum 1.1. im Jahr 0 berechnet. Aufgrund der heutigen 64bit Betriebssysteme ist eine Beschränkung auf einen kleinen Zeitraum wie 1970 nicht mehr notwendig. Allerdings wurde bei der Programmierung die Umstellung des Julianischen auf den Gregorianischen Kalender Ende des 16. Jahrhunderts nicht berücksichtigt. Daten können aber bis ca. 1600 fast sekundengenaue (Problematik der Schaltsekunde) umgerechnet werden.
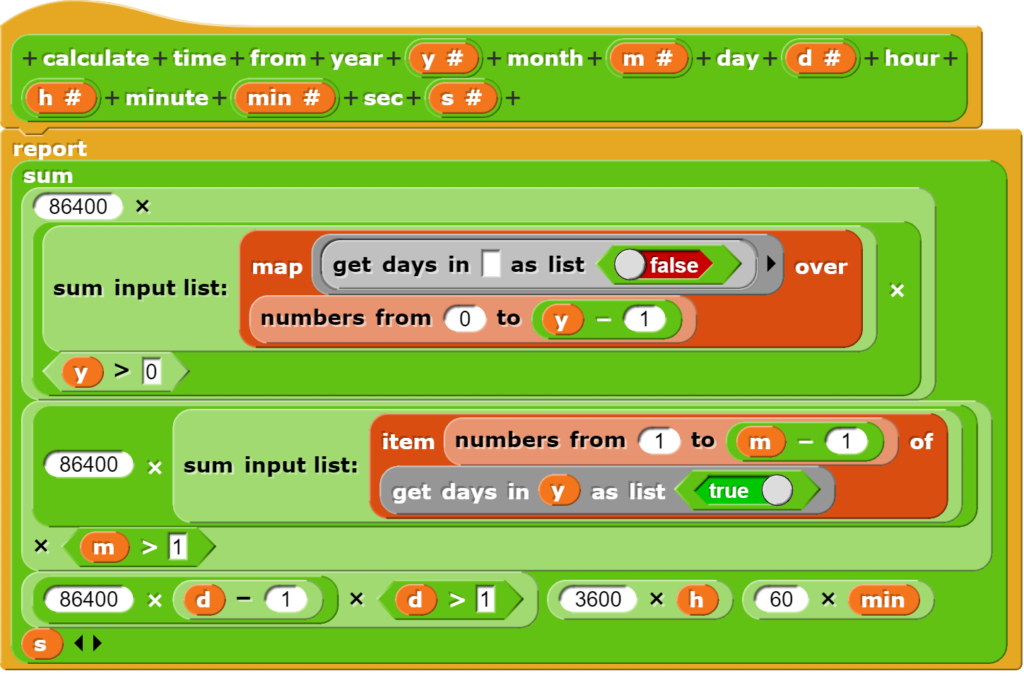
Im Wesentlichen werden alle Bestandteile einer Datums- und Zeitangabe von der Sekunde bis zum Jahr aufaddiert, wobei in Einzelfällen noch Rahmenbedingungen (Tage und Monate beginnen bei der Zählung mit 1) und Spezialfälle (wie Schaltjahre) berücksichtigt werden).
Die Problematik der Schaltjahre wurde dabei wiederum in einen eigenen Block ausgelagert.

Dabei gibt der Block die zu berücksichtigen Tage entweder als Liste (Monate) oder als Summe (Jahr) zurück.
Mithilfe dieser Blöcke kann nun der für die Lernenden eigentlich interessante Block umgesetzt werden. Dieser bietet eine etwas angenehmere Schnittstelle an, bei der die Zeitangaben einfach im in den CO2-Daten vorhandenen Zeitformat übernommen werden können.
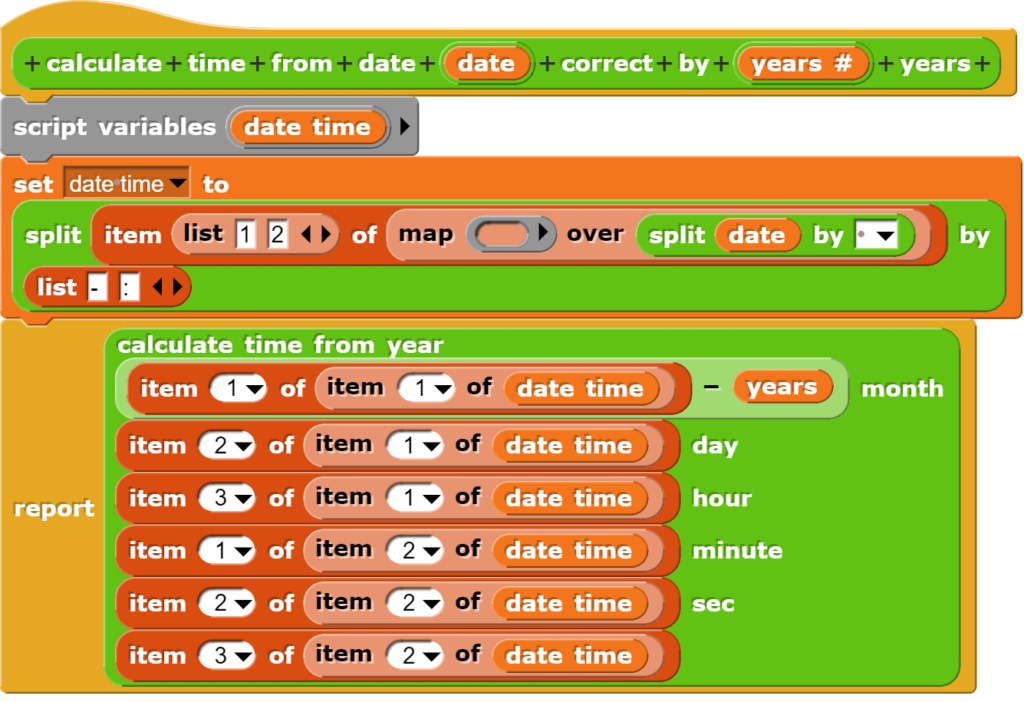
Weil dabei unter Umständen mehr als 2000 Jahre aussummiert werden müssen, kann noch mit einer Zeitkorrektur gearbeitet werden, welche die Berechnungszeit wesentlich reduziert.
Beispiel zur Bearbeitung von Daten
Eine interessante Fragestellung zu den Daten des Statistischen Amtes des Kantons Zürich ist die nach den Zeitabständen zwischen den einzelnen Messungen im Beispieldatensatz. Um mehr darüber zu erfahren, können in Snap! folgende Schritte ausgeführt werden.
- Die vorhandenen Zeitangaben werden in Sekunden umgerechnet.
- Der Datensatz wird mit diesen Angaben erweitert und die nicht mehr benötigte Spalte „time“ allenfalls entfernt.
- Die Zeitunterschiede zwischen den Messungen werden berechnet und nach der Grösse des Zeitunterschiedes oder der Häufigkeit gruppiert.
Umrechnung der Zeitangaben
Für die Umrechnung der Zeitangaben kann man auf den bereits beschriebenen Block zurückgreifen. Da alle Zeitangaben in den Beispieldaten aus dem Jahr 2020 stammen, wird die Berechnung aus Effizienzgründen um diesen Wert korrigiert. Die so entstandene Liste wird in einer temporären Variablen abgespeichert (und kann später wieder gelöscht werden).
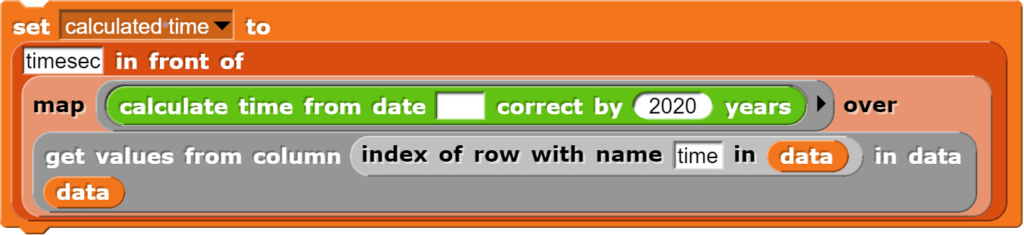
Anpassen des Datensatzes
Die so berechneten Werte fügen wir nun zur schon vorhandenen Tabelle hinzu.

Zum Löschen der nun nicht mehr benötigten Spalte „time“, kann auf bereits vorhandene Befehle zurückgegriffen werden. Um Fehler zu vermeiden, soll dabei die Spaltenzahl aufgrund der Spaltenüberschrift ermittelt werden. Dies verhindert auch Probleme, wenn sich eine Spalte nicht am Ende der Tabelle befindet und Lernende ungeduldig mehrfach einen Block anklicken.

Den Erfolg der durchgeführten Operation sollte man von Zeit zu Zeit überprüfen, was mit dem summary-Block geschehen kann.
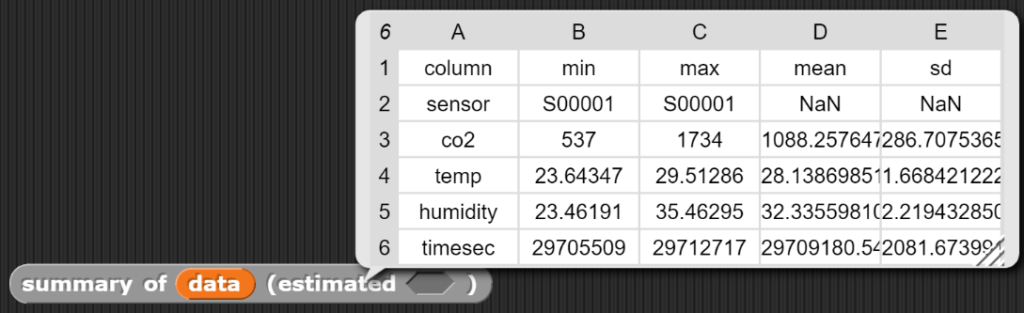
Zeitunterschiede berechnen
Im nächsten Schritt werden nun die Zeitunterschiede zwischen den Messungen berechnet. Da dazu die eigentliche Tabelle nicht benötigt wird, kann auf die temporäre Liste „calculated time“ zurückgegriffen werden.
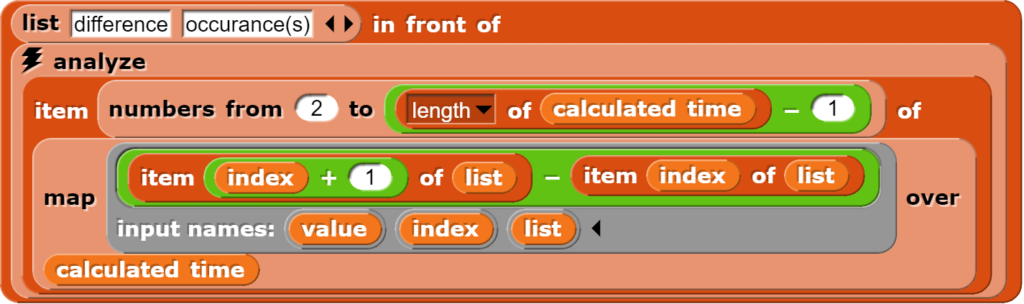
Der Block berechnet zuerst alle Differenzen zwischen jeweils nachfolgenden Zeilen, wobei der erste und letzte Wert verworfen werden, da diese Berechnungen kein sinnvolles Ergebnis liefern, dann wird ausgezählt wie viele Male jede Differenz vorkommt und die so entstandene Tabelle noch mit entsprechenden Überschriften versehen.
Fazit
Anhand der CO2-Daten des Statistischen Amtes des Kantons Zürich wurde aufgezeigt, wie Snap! als Alternative zu einer professionellen Statistiksoftware wie R für die deskriptive Datenanalyse verwendet werden kann. Fehlende Funktionalitäten können dabei auf beliebigem Abstraktionsniveau ergänzt werden. Aufgrund der Flexibilität von Snap! kann damit eine typische Vorgehensweise von R gut nachgebildet werden, ohne dass man sich dabei die Schwierigkeiten einer textbasierten Programmiersprache einhandelt.
Damit eignet sich Snap! gut für die Datenanalyse mit Schülerinnen und Schülern der Sekundarstufe I und das dabei erworbene Wissen und die erarbeiteten Kompetenzen – z.B. zur genauen Funktionsweise des map-Blockes – sollten sich anschliessend vergleichsweise gut auf eine Statistiksoftware wir R übertragen lassen.
Die folgenden Einschränkungen sollten aber beachtet werden:
- Alle beschriebenen Blöcke funktionieren unter der Voraussetzung, dass die Daten sauber sind, d.h. keine fehlenden oder falschen Daten (z.B. Text statt Zahlen) enthalten. In dieser Hinsicht leistet R mehr, weil entsprechende Mechanismen teilweise schon eingebaut sind.
- Da Snap! in einem Browser läuft und technisch auf eine JavaScript-Umgebung aufbaut, ist R in der Regel erstens schneller und kann zweitens auch mit wesentlich grösseren Datenmengen umgehen.
- R verfügt mit seinen zahlreichen Erweiterungen natürlich über wesentlich mehr Statistikfunktionen als dies bei dem Allrounder Snap! der Fall ist.
Trotz dieser Einwände lohnt sich der Einsatz von Snap, denn …
- Auch in R ist die Säuberung von Datensätzen mit grossem Aufwand verbunden und teilweise eine Aufgabe für Expertinnen und Experten.
- Die Datenmengen, welche auf der Sekundarstufe I in der Regel bearbeitet werden, dürften weit unter dem technisch umsetzbaren Grenzen bei der Programmierung mit Snap! liegen.
- Auf der Sekundarstufe I wird nur ein Bruchteil der statistischen Methoden benötigt, die in einem professionellen Umfeld verwendet werden. Ausserdem können die gewünschten Funktionen als Blöcke jederzeit nachprogrammiert werden.
- Im Gegensatz zu R sind weitere Anwendungsfelder beispielsweise im Bereich Multimedia einfacher umzusetzen und bedürfen dafür auch nicht der vorgängigen Installation einer zusätzlichen Software auf den Geräten der Lernenden.
Insgesamt spricht also vieles für den Einsatz von Snap! auf der Sekundarstufe I und dies auch im Bereich der deskriptiven Statistik. Dass dies bisher wohl kaum geschehen ist, dürfte vor allem daran liegen, dass der Fokus der Volksschule bisher einerseits wenig auf der Programmierung lag, wobei die deutliche Abgrenzung zwischen Medien und Informatik im Lehrplan nicht unbedingt hilfreich ist, und wenn die eigentliche Informatik doch einmal im Vordergrund stand, sich diese auf die Umsetzung als „Informatik ohne Strom“ oder aber auf vergleichsweise banale Umsetzungen in blockbasierten Sprachen wie Scratch beschränkte, bei denen meist nur sehr einfache Konzepte der Informatik umgesetzt wurden.
Es ist zu hoffen, dass mit dem steigenden Bekanntheitsgrad von Snap! die dadurch eröffneten Möglichkeiten zunehmend auch im deutschsprachigen Raum eingesetzt und damit der künstliche Graben zwischen Medien und Informatik überwunden werden kann, denn die Datenanalyse mit Snap! ist nur eine von äusserst vielfältigen Anwendungsmöglichkeiten und die dabei erworbenen Erkenntnisse können anschliessend gut auch im Bereich der Medien genutzt und erweitert werden.
Die beschriebenen Blöcke können unter Data Science ausprobiert werden.