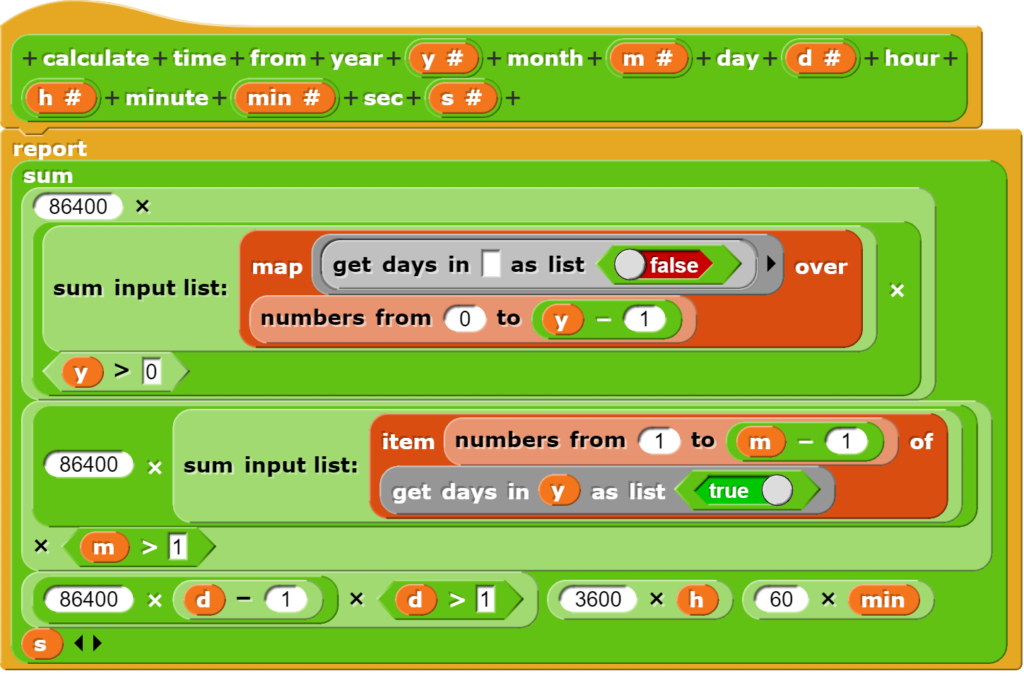
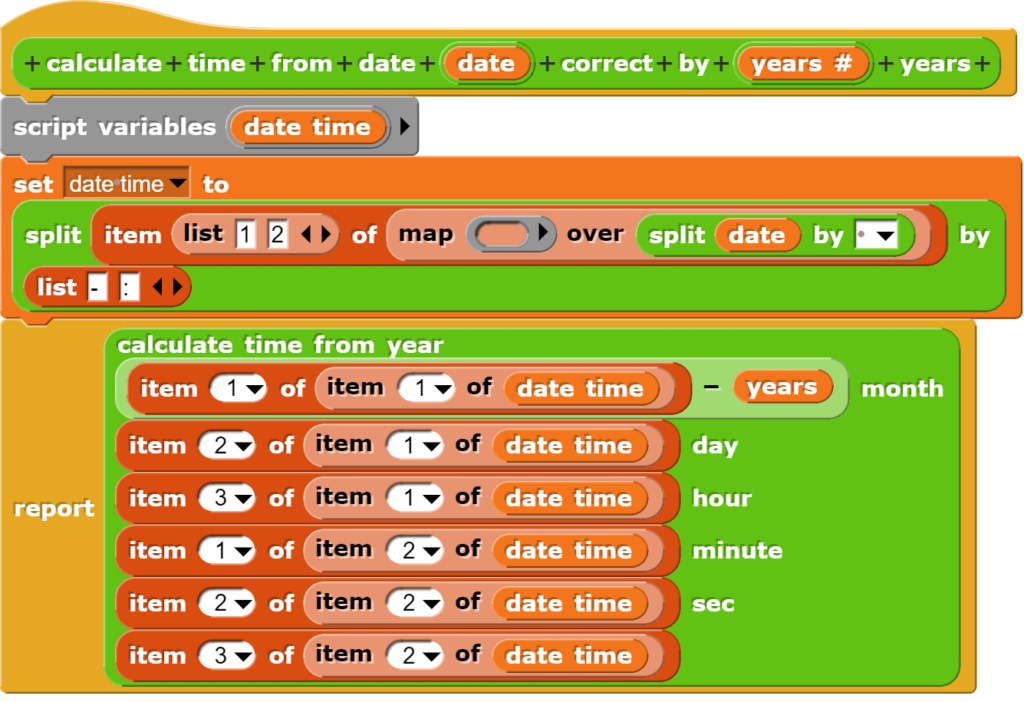
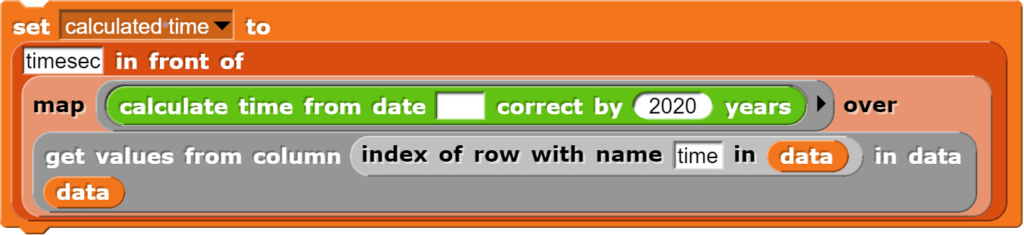
CO2-Messungen in Schulen haben im Verlauf der Covid-19-Pandemie an Bedeutung gewonnen, weshalb nebst kommerziellen Geräten unterdessen verschiedene Bauanleitungen zu Verfügung stehen. Der hier vorgestellte Lösungsansatz unterscheidet sich von anderen Geräten dadurch, dass er folgende Anforderungen erfüllt:
Das Gerät soll die tatsächliche CO2-Konzentration einigermassen genau messen und diese nicht aus anderen Werten (z.B. dem Vorhandensein von Wasserstoff) ableiten.
Die Messdaten sollen auf unterschiedliche Weise ausgewertet werden können: direkte Anzeige, grafischer Verlauf, weitere Auswertung am Computer.
Das Gerät soll in einer blockbasierten Sprache von Schülerinnen und Schülern der Sekundarstufe I selbst programmiert werden können.
Teile des Gerätes sollen im MINT-Unterricht auch für andere Zwecke verwendet werden können.
Um diese Anforderungen zu erfüllen, wird eine Kombination aus dem Mikrocomputer Adafruit CLUE, der mit MicroBlocks programmiert wird und dem CO2-Sensor SCD-30 verwendet. Dies ist dank der von Markus Gälli freigegebenen Bibliothek für den CO2-Sensor seit Dezember 2021 möglich: https://github.com/MarkusGaelli/MicroBlocks-SCD30, wobei die Bibliothek voraussichtlich in der nächsten Version von MicroBlocks offiziell aufgenommen wird.
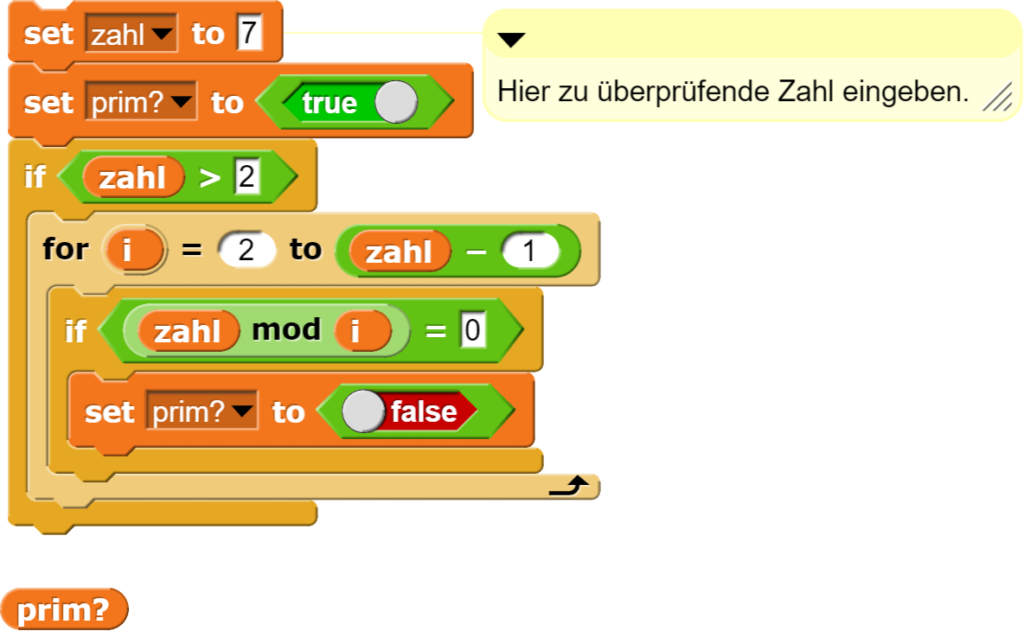
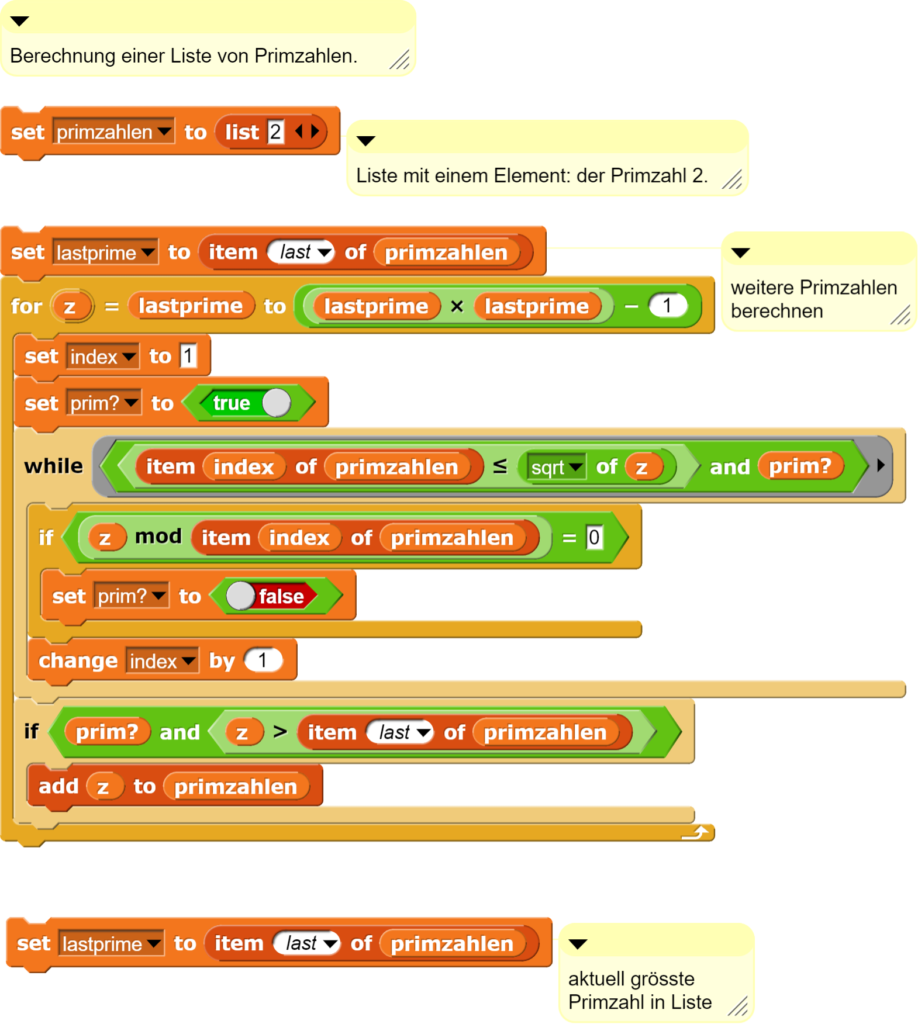
Das CO2-Messgerät und seine Funktionen
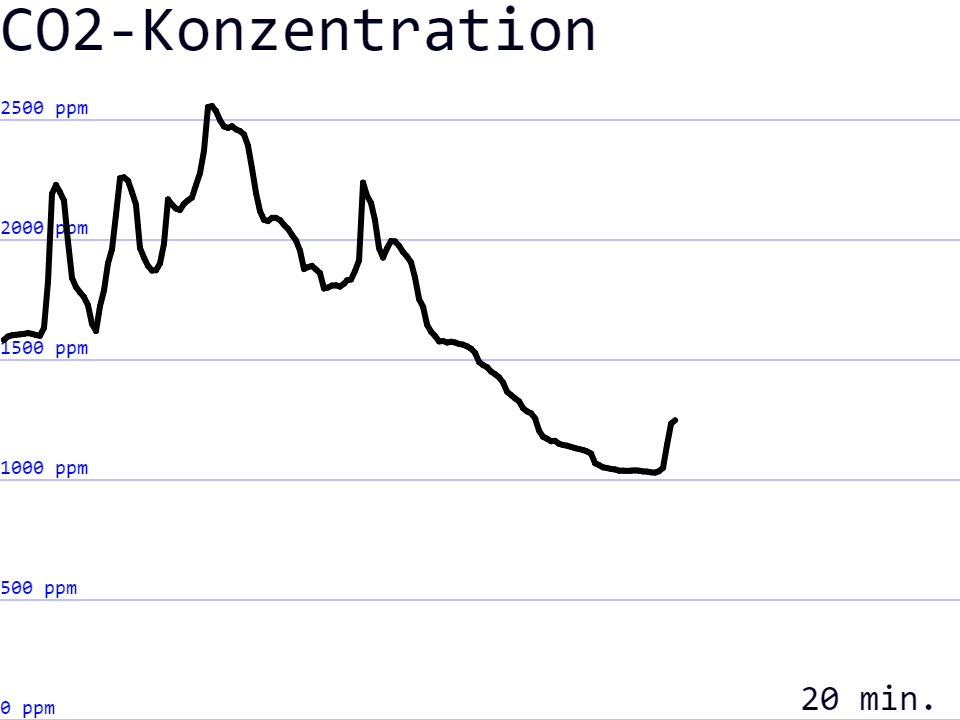
In der hier beschriebenen Version können die Messdaten auf dem Bildschirm des Adafruit CLUEs als Zahlenwerte und grafisch ausgegeben werden.
Der CO2-Sensor SCD30 wird mit dem Adafruit CLUE über ein STEMMA-to-Groove-Kabel verbunden und ist damit über die I2C-Schnittstelle ansprechbar.
Die Daten können via die MicroBlocks-Umgebung direkt an den Computer übergeben werden, an den der Adafruit CLUE mittels USB-micro-Kabel angeschlossen wird und von dort aus als CSV-Datei für die weitere Datenauswertung abgespeichert werden. Ausserdem verfügt die vorgestellte Variante über eine einfache Menüführung, welche flexibel ausgebaut werden kann.
MicroBlocks
Microblocks (https://microblocks.fun) ist eine blockbasierte Programmierumgebung für Mikrocomputer wie den micro:bit, Calliope und andere ähnliche Geräte, bei der Programme sofort ausgeführt werden können und die recht performant ist. Unterdessen stellt die Webseite auch diverse Anleitungen für den Unterricht (teilweise in deutscher Sprache) zu Verfügung. Wie der Mikrocomputer von MicroBlocks aus angesprochen wird, ist beispielsweise hier beschrieben: QuickStart.
Das Hauptprogramm nebst bereits vorhandenen einige zusätzliche Bibliotheken:
SCD30.ubl von Markus Gälli
Stellt die Blöcke zum Ansprechen und Auslesen des SCD30 zu Verfügung.
digits.ubl
Erlaubt die Anzeige der Ziffern 0-9 in beliebiger Grösse als Digitalzahlen.
drawGraph.ubl
Stellt eine in der Höhe anpassbare Grafik für den Adafruit CLUE zu Verfügung.
menuOptions.ubl
Erlaubt die Programmierung eines einfachen Menüsystems für den Adafruit CLUE.
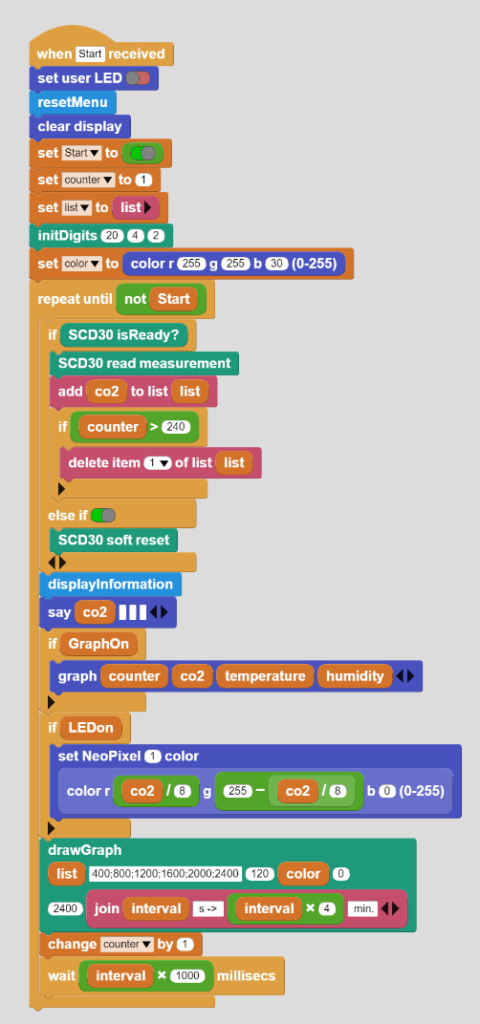
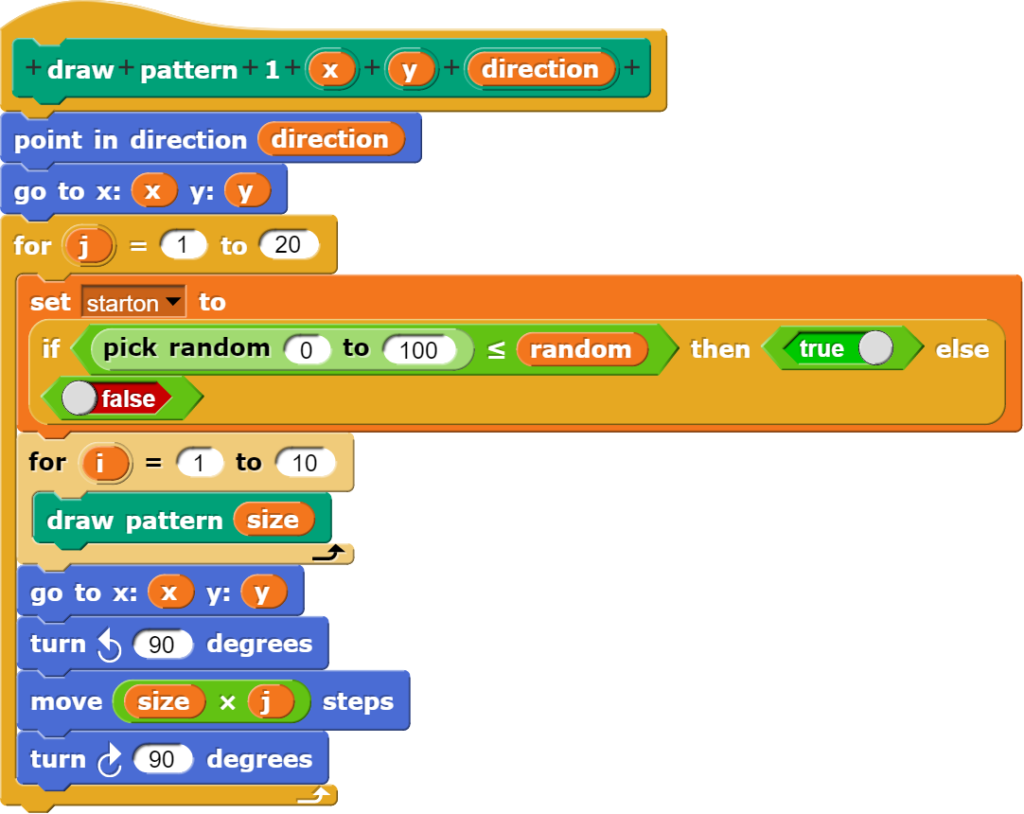
Die eigentliche Messung wird in einem Block mit verschiedenen Unterbefehlen durchgeführt.
Das Hauptprogramm zeigt die gemessenen Werte als Zahl und Grafik an und kann die Messwerte auch zur weiteren Bearbeitung an einen Computer übergeben.
Zuerst werden diverse Parameter gesetzt und dann die Messwerte innerhalb einer repeat-until-Schleife ausgelesen, wobei jeweils die letzten 240 Werte in einer Liste gespeichert werden. Dabei stehen folgende Darstellungsmöglichkeiten der Messwerte zu Verfügung:
Anzeige als Text auf dem Bildschirm des Adafruit CLUE mittels displayIniformation;
direkte Ausgabe auf dem Bildschirm des Computers, falls der CLUE damit verbunden ist über say;
Weitergabe der Messwerte an das Graphmodul von Microblocks;
Ausgabe des aktuellen Messwertes als Farbinformation via NeoPixel-LED;
grafische Ausgabe der letzten 240 Messwerte auf dem Bildschirm des Adafruit CLUE.
Das Zeitintervall für die Messungen kann schrittweise von 5 – 120 Sekunden festgelegt werden, wodurch die grafische Ausgabe einen Zeitraum von 20 Minuten bis 8 Stunden abdeckt.
In der vorliegenden Version kann der Adafruit CLUE mit den Tasten A und B über ein einfaches Menü gesteuert werden.
Dabei kann jeweils über die Taste A der nächste Wert angesteuert und dieser über die Taste B ausgewählt werden. Das Drücken beider Tasten gleichzeitig führt zurück ins Hauptmenü.
Die Möglichkeiten, Messdaten über Funk an einen anderen Mikrocomputer zu senden, ist aktuell noch nicht implementiert, kann aber mit wenigen Befehlen (unter allfälliger Anpassung des Menüs) durchgeführt werden.
Verwendung im Unterricht
Erst einmal kann das Gerät für die CO2-Messung im Schulzimmer verwendet werden, um die Luftqualität zu überprüfen. Ob dabei die genaue Anzeige der aktuellen Messwerte, die Grafik (Zeitreihe von Messwerten) oder die NeoPixel-LED als Anhaltspunkt dient, hängt vom genauen Einsatzzweck ab.
Auswertung der Daten in Snap!, wobei die gleichen Algorithmen wie bei der grafischen Anzeige auf dem Adafruit CLUE verwendet werden.
Dann können die Schülerinnen und Schüler das Gerät aber auch verwenden, um mittels gezielter CO2-Messungen eigenen Fragestellungen nachzugehen. Die relativ einfach anpassbare Programmierung erleichtert dabei auch die Untersuchung etwas speziellerer Fragestellungen. Allerdings eignet sich der SCD30-Sensor nicht für schnelle Messungen, da die Messintervalle ca. 2 Sekunden betragen. Da die Messwerte als CSV-Datei gespeichert werden können, steht einer weiteren Auswertung nichts mehr im Wege.
Letztlich kann das Gerät auch als Beispiel für die Programmierung von Mikrocomputern im Informatikunterricht eingesetzt werden, wobei auf Fragestellungen wie Timing, Anzeige von Messwerten, Datenübermittlung usw. fokussiert werden kann.
Verschiebt man Punkte entlang eines Vektorfeldes entstehen häufig interessante Muster, wie sie beispielsweise von Magnetlinien bekannt sind. Die Programmierung interessanter Vektorfelder ist aber nicht ganz einfach. Da liegt es nahe, Bilder als Quelle für solche Vektorfelder zu verwenden. Fotos eignen sich dafür besonders gut, weil die Farbinformation der einzelnen Fotopixel auf mehrere verschiedene Arten ausgewertet werden können.
Die aus den Vektorfeldern resultierenden Linienmuster werden dabei mit Snap! erzeugt.
Grundlagen
In Snap! können Fotos importiert werden, indem sie einfach auf die Programmieroberfläche gezogen werden. Anschliessend kann dieses Foto einem Sprite mit den folgenden Befehlen zugeordnet werden.
Ein bereits in Snap! importiertes Foto kann über den entsprechenden Block als Kostüm verwendet werden.
Der stretch-Block sorgt dafür, dass das Foto die ganze Bühnenoberfläche (stage) komplett ausfüllt.
Nun kann die Eigenschaft einzelner Pixel im geladenen Foto mit folgendem Programm überprüft werden.
Das Programm fragt den Farbwert eines einzelnen Pixels im gegebenen Foto ab.
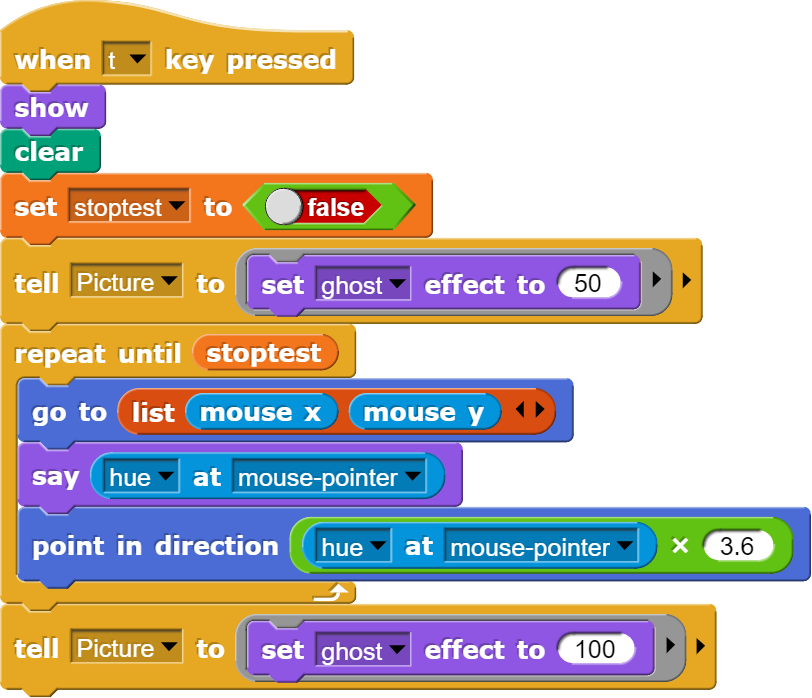
Sobald im Programm die Taste t (für Testen) gedrückt wird, bewegt sich das Objekt (sprite) zur aktuellen Mausposition, liest dort den Farbwert (hue) des an der Mausposition befindlichen Pixels aus und zeigt diesen an. Die weiteren Blöcke im Programm werden für das Zusammenspiel mit den anderen Programmteilen benötigt.
Das Objekt zeigt in die Richtung des gemessenen Farbwerts und gibt diesen aus.
Weil die hue-Farbwerte von 0 bis 100 reichen, wird der Messwert noch mit 3.6 multipliziert, damit als Richtung die vollen 360° erreicht werden können.
Wenn sich das Objekt nun in Richtung des gemessenen Werts bewegt, anschliessend eine neue Richtungsbestimmung vornimmt und diesen Vorgang beliebig viele Male wiederholt, entsteht eine Spur auf dem Bild.
Auf dem Hintergrund sind bereits mehrere zurückgelegte Spuren zu sehen.
Damit diese Möglichkeit interaktiv ausprobiert werden kann, ist folgende Programmierung notwendig.
Das Objekt (sprite) kann mit der Maus positioniert werden. Sobald die Maustaste nicht mehr gedrückt wird, zeichnet das Programm eine Spur auf das Foto.
Die bisher von Hand gewählte Positionierung wird nun per Programm vielfach durchgeführt.
Einfache Linienmuster
Das folgende Programm sorgt zuerst dafür, dass einige Umgebungsvariablen richtig gesetzt sind und führt dann die oben beschriebenen Schritte innerhalb des warp-Blockes (dient der beschleunigten Bildschirmausgabe) mehrfach aus.
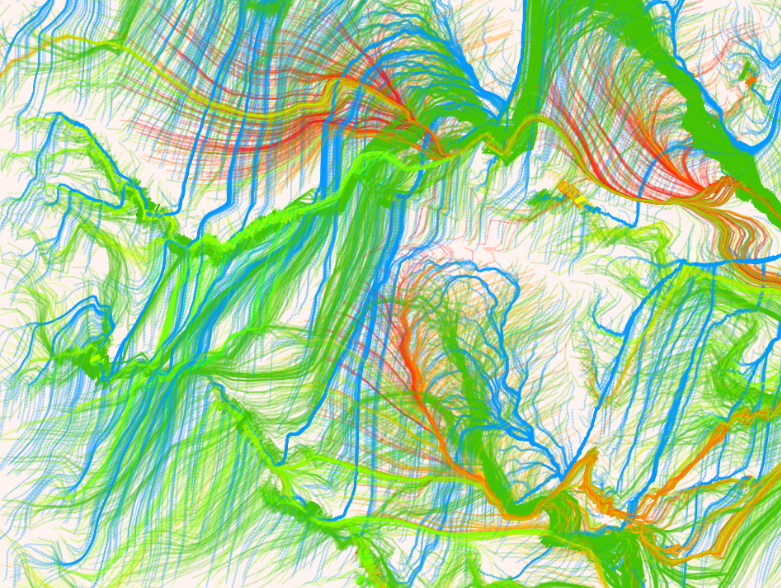
Ausgehend von Zufallspunkten werden Linien gezeichnet, welche dem Vektorfeld folgen.
Je nach verwendeter Fotovorlage, dem gewählten Kriterium (hier: Helligkeit) und der verwendeten Schrittlänge entstehen unterschiedliche Linienmuster.
Diesem Bild liegt das im Programm verwendete Eisbild zugrunde (heller Hintergrund).Für dieses Bild diente das Foto mit dem Hund und der Ziege als Grundlage (dunkler Hintergrund).
Obwohl bei beiden Bildern (abgesehen vom Hintergrund) die genau gleichen Parameter gewählt wurden, sind völlig unterschiedliche Linienmuster entstanden.
Gleichzeitige Verwendung mehrere Linienmuster
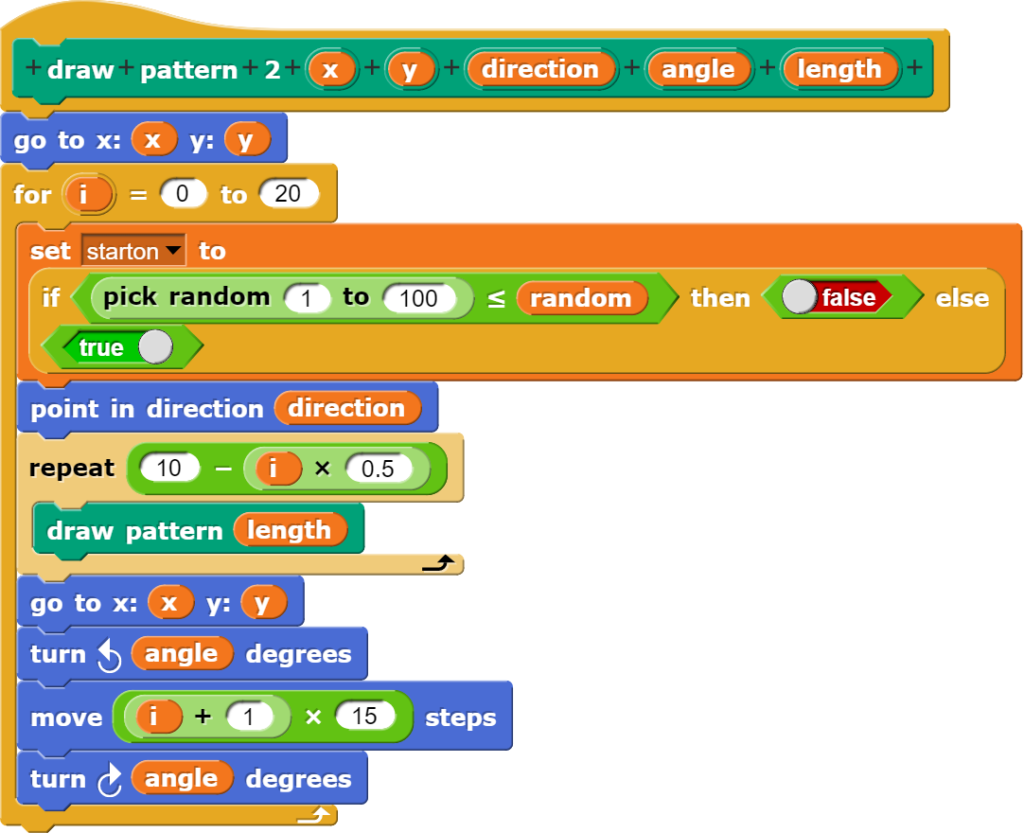
Statt jeweils nur einen Parameter für die einzelnen Pfade (Linien) zu verwenden, kann dabei auf unterschiedliche Informationen zugegriffen werden. Dazu bietet es sich an, einen Block zu programmieren, welcher das Abfragen der unterschiedlichen Merkmale eines Bildpixels vereinfacht.
Der Block erlaubt die Wahl der gewünschten Farbinformation über ein Menü.
Als Auswahlmöglichkeiten stehen folgende Optionen zu Verfügung:
hue: Farbwert von 0 bis 100 entlang des Spektrums eines Regenbogens;
saturation: Farbigkeit von 0 bis 100, bestimmt, ob eine Farbe gräulich oder lebendig erscheint;
brightness: Helligkeit der gewählten Farbe;
red: Rotwert des Pixels;
green: Grünwert des Pixels;
blue: Blauwert des Pixels.
Die Werte für hue, saturation und brightness werden am besten mit 3.6, die für red, green und blue mit 1.41 multipliziert.
Diesen Block kann nun im oben abgebildeten Programm zum Zeichnen von Linien verwendet werden, oder er wird in eine erweiterte Version eingesetzt, welche gleichzeitig mehrere Kriterien für den Verlauf der einzelnen Pfade definiert.
Das Programm wählt ein Richtungskriterium und die gewünschte Einfärbung per Zufalls aus einer Liste von Möglichkeiten aus.
Der dem zurückgelegten Pfad (Linie) zugrunde liegende Farbwert, das Kriterium für die Richtungswahl bei den einzelnen Schritten, sowie die Schrittweite werden jeweils per Zufall ausgewählt. Dadurch entsteht bei geschickt gewählten Parametern anstelle eines blossen Linienmusters eine Art von Netz, wie sie beispielsweise häufig bei Stoffen zu finden ist.
Einige Beispiele sollen dieses Prinzip verdeutlichen (bei allen wurden die im abgebildeten Programm gezeigten Parameter verwendet).
Für dieses Muster wurde das Foto des Eichhörnchens verwendet (dunkler Hintergrund).Für dieses Muster diente das Apfelbild als Grundlage (heller Hintergrund).Hier wurde das Eisbild als Grundlage verwendet (dunkler Hintergrund).
Welche Muster ein entsprechendes Foto erzeugt, lässt sich im Voraus nur schwer erahnen. Klar abgegrenzte Objekte in einem Foto erzeugen aber klarere Richtungswechsel und prominente Muster in den erzeugten Grafiken.
Auf das beschriebene Programm kann hier zugegriffen werden: Photo to vector field.
Alle im Programm verwendeten Fotografien stammen von Ernst Giger.
Verwendung im Unterricht
Nebst dem reinen Experimentieren und der Neugier, welches Foto mit welchen Parametern zu welchen Mustern führt, kann das Programm auch dazu verwendet werden, Eigenschaften von Vektorfeldern systematisch zu untersuchen.
Statt einzelne Punkte zufällig zu wählen, können die Startpositionen auf bestimmten geometrischen Orten wie Linien oder Kreisen liegen.
Das gleiche Bild kann mehrfach mit den gleichen Startwerten als Grundlage für die Berechnung verwendet werden.
Bei unterschiedlichen Fotos kann untersucht werden, wie sich die Schrittlänge auf die Stabilität der Muster auswirkt.
Solche Untersuchungen können schnell zu Diskussionen darüber führen, wie einheitlich die Musterbildung in einzelnen Vektorfeldern ist und damit die Stabilität unterschiedlicher Systeme (hier Fotos) zu diskutieren.
Schliesslich kann auch der umgekehrte Weg gegangen werden. Gelingt es den Schülerinnen und Schülern ein Bild (oder Foto) anzufertigen, dass zu einem gewünschten Verhalten in Bezug auf den Linienverlauf einzelner Grafiken führt?
Primzahlen bilden eine Grundlage der Mathematik und sind deshalb auch auf der Sekundarstufe I ein Thema. Allerdings beschränkt sich die Auseinandersetzung auf dieser Stufe häufig darauf, die Primzahlen mithilfe des Siebes von Eratosthenes zu gewinnen und diese anschliessend für die Primfaktorzerlegung von natürlichen Zahlen zu verwenden. Dabei bietet sich das Thema auf gut dafür an, die Berechnung von Primzahlen mit dem Computer und zu thematisieren und dabei über die Optimierung von Algorithmen zu diskutieren.
Naiver Ansatz
In einem ersten Versuch verwenden wir einen ganz einfachen Algorithmus. Wir nehmen zuerst einmal an, jede Zahl sei eine Primzahl. Dann teilen wir diese Zahl durch alle Zahlen, die kleiner als die gewünschte Zahl selbst sind. Sollten bei diesen Divisionen der Rest irgendwann 0 sein, verwerfen wir die Annahme, dass es sich um eine Primzahl handelt.
Ob es sich bei einer Zahl um eine Primzahl handelt, kann einfach geprüft werden.
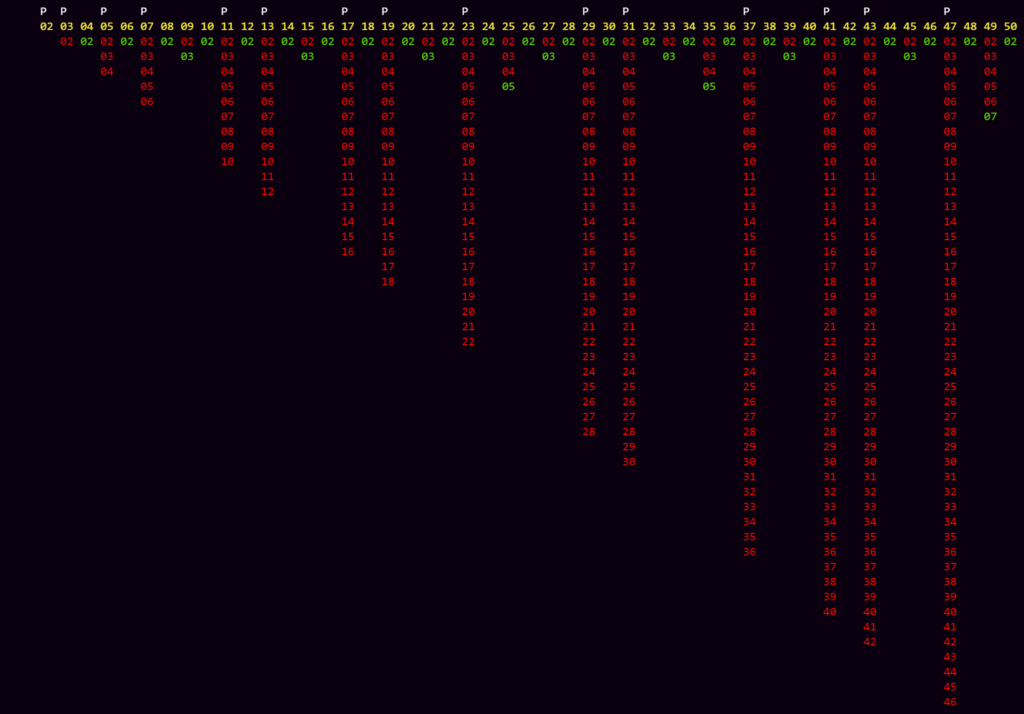
Dieser einfache Algorithmus funktioniert für Zahlen > 1 gut, ist aber sehr langsam, da viele unnötigen Berechnungen durchgeführt werden. Dies sieht man, wenn man alle Zahlen aufführt, welche bei den Divisionen verwendet werden.
In der einfachen Version des Algorithmus zur Primzahlenbestimmung steigt der Rechenaufwand linear an.
Es fällt sofort auf, dass viele unnötige Rechenschritte durchgeführt werden, weil beispielsweise alle geraden Zahlen (ausser der 2) sicherlich keine Primzahlen sind. Trotzdem wird beispielsweise bei der 50 noch lange weitergerechnet, selbst wenn schon früh klar ist, dass es sich nicht um eine Primzahl handeln kann.
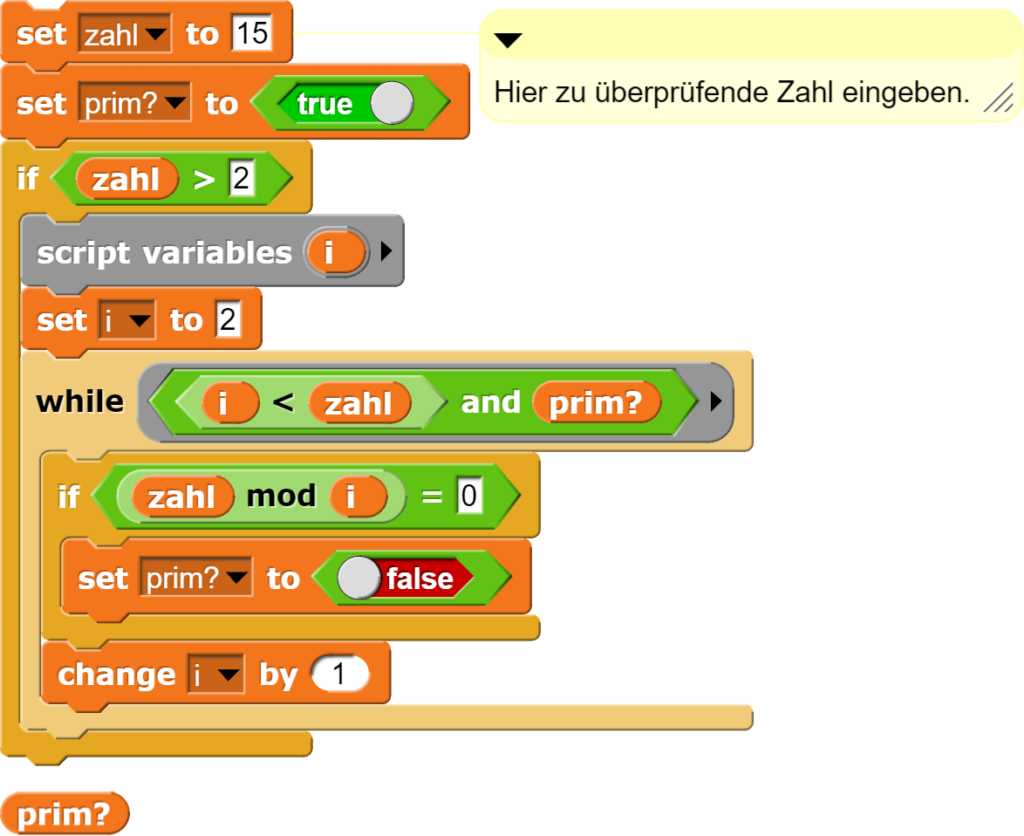
Möglichst frühzeitiger Abbruch
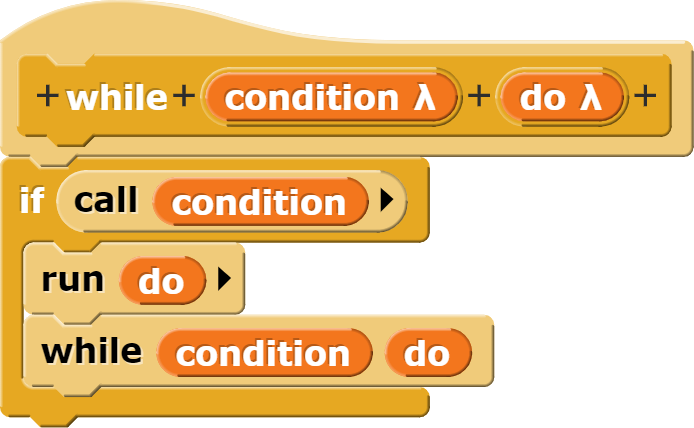
Die Vermeidung unnötiger Rechenschritte bedingt die Neuformulierung des Algorithmus. Dafür muss die for-Schleife in Snap! durch eine while-Schleife ersetzt werden. Allerdings steht diese nicht standardmässig zu Verfügung, weshalb diese zuerst programmiert werden muss. In Snap! funktioniert dies wie folgt:
Der neue while-Block wird rekursiv programmiert.
Mit der durch die while-Schleife mögliche Anpassung des Algorithmus werden unnötige Rechenschritte verhindert.
Dies wird deutlich, wenn man sich noch einmal alle Zahlen anschaut, die nun in den notwendigen Divisionen verwendet werden.
Im Gegensatz zum ersten Versuch werden nur noch bei Primzahlen selbst viele Berechnungen durchgeführt.
Bei allen Zahlen, welche keine Primzahlen sind, wird die Berechnung schon sehr früh abgebrochen. Dies ist auch deshalb von Interesse, weil Primzahlen seltener werden, wenn man grössere Zahlen untersucht. Das wird bereits in der oben abgebildeten Grafik deutlich:
Um das Programm weiter zu optimieren, ist eine mathematische Betrachtung von Teilern notwendig.
Eigenschaften von Teilern
Die Teiler einer bestimmten Zahl treten immer paarweise auf, wobei es vorkommen kann, dass die beiden Teiler gleich gross sind:
Teiler von 12: 1 und 12, 2 und 6, 3 und 4.
Teiler von 25: 1 und 25, 5 und 5.
Zu jedem grossen Teiler gehört also ein entsprechend kleiner Teiler. Bei der Quadratzahl 25 ist gut ersichtlich, dass zum Teiler 5 kein Teiler vorhanden ist, der grösser als 5 ist, sonst müsste es sich, z.B. bei 5 x 6 um eine grössere Zahl handeln.
Damit ist es möglich, die zu überprüfenden Teiler weiter einzuschränken. Statt bei Primzahlen bis zu n-1 zu prüfen, reicht eine Prüfung bis zur Quadratwurzel von n aus.
Die Änderung im Algorithmus beschränkt sich dabei auf das Abbruchkriterium in der while-Schleife.
Dadurch verringert sich der Rechenaufwand bei den bisher aufwändigen Primzahlen noch einmal dramatisch, was die Auflistung der benötigten Teiler zeigt:
Gegenüber der ursprünglichen Variante hat sich die Anzahl der Rechenschritte drastisch reduziert.
Eine weitere Optimierung ist möglich, indem man nicht mehr alle Zahlen als Teiler verwendet, sondern nur noch die Primzahlen selbst. Dabei stellt sich aber die Frage, woher dann diese Primzahlen im Voraus bekannt sein sollen.
Nimm 2
Mit einem entsprechenden höheren Aufwand beim Schreiben des Algorithmus ist es tatsächlich möglich, die Primzahlen aus sich selbst heraus zu erzeugen. Als Voraussetzung wird dazu nur eine Liste mit dem Element 2 benötigt. Alle weitere Primzahlen kann das folgende Programm daraus generieren.
Während die Zeit für die Berechnung insbesondere für grössere Primzahlen weiterhin sinkt, ist der dafür notwendige Algorithmus wesentlich komplexer geworden.
Nach dem ersten Durchlauf des Programms besteht die Liste aus den Zahlen 2 und 3, denn es wird bis maximal zur Zahl 3 geprüft und diese ist nicht durch 2 teilbar. Nach dem zweiten Durchlauf sind die Primzahlen 5 und 7 dazugekommen, denn das Programm prüft nun bis 8. Der nächste Durchlauf prüft bis 48 und liefert als letzte Primzahl 47 zurück. Bei jedem weiteren Durchlauf wird der untersuchte Zahlenraum grösser und damit die Liste der Primzahlen länger. So können aus der 2 alle weiteren Primzahlen generiert werden.
Nebst der schnelleren Berechnung hat dieser Ansatz auch den Vorteil, dass die Berechnung der Primzahlen jederzeit angehalten und später wieder fortgesetzt werden kann. Denn alles, was das Programm dafür benötigt, ist die Liste mit den Primzahlen, aus welcher es die grösste Primzahl ausliest, um weitere Berechnungen anzustellen.
Im gezeigten Beispiel darf der Computer dazu nicht ausgeschaltet werden, da sich die Liste im flüchtigen Speicher befindet. Die geführte Liste könnte aber auch auf eine Harddisk geschrieben werden, wodurch das Programm seine Arbeit auch nach einem tatsächlichen Unterbruch wieder aufnehmen könnte.
Laufzeiten
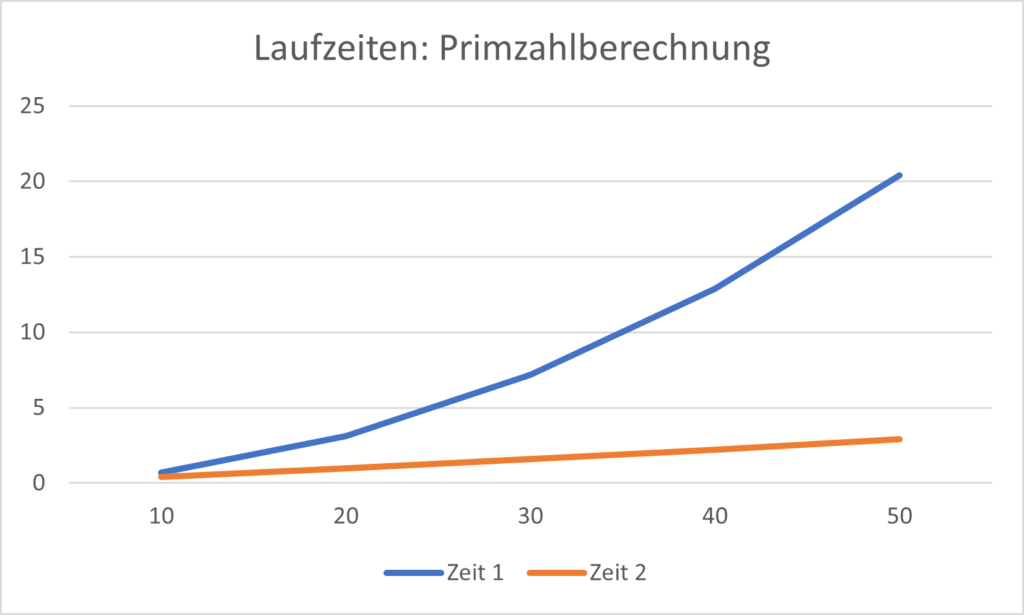
Die Laufzeiten der unterschiedlichen Varianten unterscheiden sich dramatisch. Gemessen wurde jeweils die Zeit, welche zur Berechnung der ersten n Primzahlen notwendig war.
Die Laufzeiten zur Berechnung von Primzahlen steigen in Abhängigkeit vom verwendeten Algorithmus unterschiedlich stark an.
Während bei der einfachsten Version die Laufzeiten immer stärker zunehmen, verhalten sich diese in der optimierten Fassung zumindest im untersuchten Zahlenbereich fast linear. Diese Unterschiede sind bei kleinen Zahlenbereich noch klein, werden aber schnell immer grösser.
Anwendung im Unterricht
Die vorgestellten Ansätze können nicht nur dafür verwendet werden, bei grösseren Zahlen herauszufinden, ob es sich dabei um Primzahlen handelt. Sie bieten auch eine gute Gelegenheit dafür, mit den Schülerinnen und Schülern die Notwendigkeit der Optimierung von Programmen zu besprechen.
Diese spielt bei vielen Computeranwendungen eine wichtige Rolle, nicht nur weil dadurch Energie und die damit verbundenen Kosten eingespart werden können, sondern dadurch werden auch Anwendungen möglich, die vorher aus Zeitgründen nicht praktikabel umgesetzt werden konnten.
Die Sashiko-Verziertechnik wurde in Japan verwendet, um schadhafte Textilien auszubessern. Interessant an Nähtechnik ist, dass sie in der Form von Binärzahlen dargestellt werden kann. Aufgegriffen hat das Thema Jens Mönig im Juni 2021.
Die Grundlagen
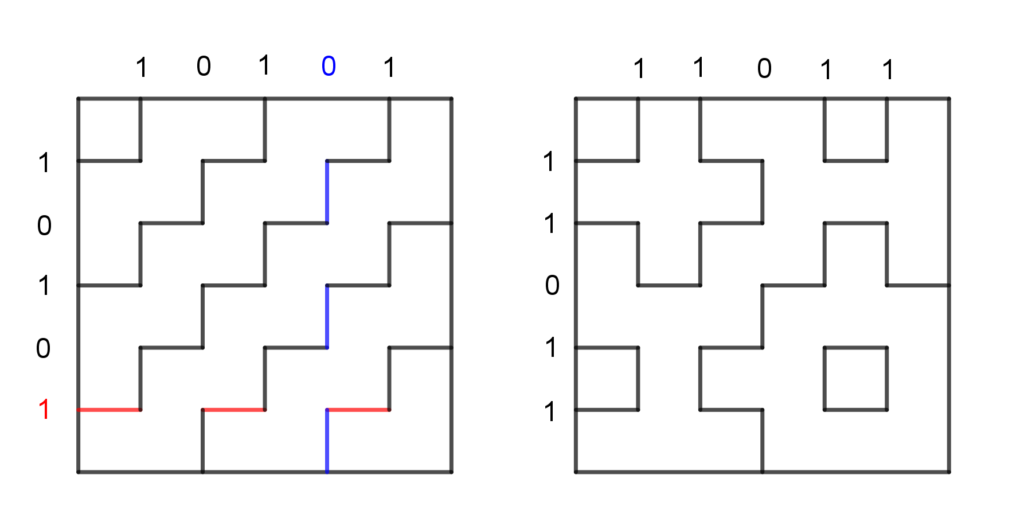
Traditionell werden Stiche gleicher Länge verwendet (Sashiko heisst auf Japanisch Stäbchen), wobei der Faden einmal auf der Ober- und einmal auf der Unterseite zu sehen ist. Dabei kann man jeweils mit einem Unter- oder Oberstich beginnen. Es gibt also zwei Möglichkeiten (Binärsystem). Führt man nun mehrere solcher Stichfolgen horizontal und vertikal aus, können ganz unterschiedliche Muster entstehen.
Beispiele für Sashiko-Muster: Bei der 1 (rot) beginnt man mit einem Oberstich, bei der 0 (blau) mit einem Unterstich.
Experimente mit verschiedenen Bit-Folgen können mit dem Snap!-Beispiel von Jens Mönig durchgeführt werden: Hitomezashi Sashiko.
Zufällige Muster
Im Dezember 2021 griff Ayliean MacDonald von Numberphile das Thema (siehe YouTube) und überlegte sich, ob solche Muster nicht auch zufällig erzeugt werden könnten. Dabei interessiert sie sich vor allem dafür, wie viel Ordnung, respektive Chaos bei unterschiedlich zufälligen Bitmustern entstehen.
Beispiel für ein Sashiko-Muster, bei dem mit 50%-Wahrscheinlichkeit mit einem Oberstich begonnen wird.
In Abweichung von der Anzahl der Stiche können so sehr viele unterschiedliche Muster entstehen, ohne dass diese von Hand „programmiert“ werden müssen.
Vom Quadrat zum Dreieck
Nebst der Einführung des Zufalls erweitert MacDonald die Sashiko-Muster auch, indem sie statt einem Quadrat ein gleichseitiges Dreieck als Ausgangsform verwendet. Dadurch entstehen Muster aus der Kombination von drei Stichrichtungen.
Bei der Verwendung eines Dreiecks als Grundfigur ergeben sich ebenfalls interessante Zufallsmuster.
Die Programmierung
Die Programmierung eines Stiches bestehend aus Ober- und Unterstich oder umgekehrt bildet die Grundlage der sowohl der Quadrat- als auch der Dreiecksmuster.
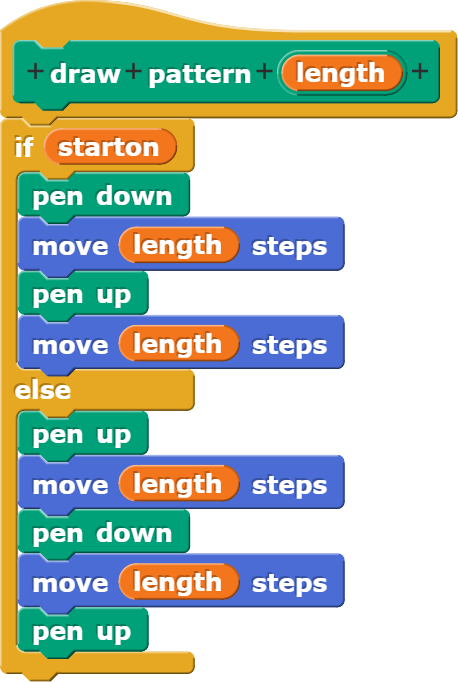
Ob mit einem Ober- oder Unterstich begonnen wird, ist vom Wahrheitswert starton abhängig.
Darauf aufbauen wird dann die weitere Programmierung vorgenommen. Beim Quadrat ist diese recht einfach, denn es müssen nur horizontale und vertikale Stichfolgen programmiert werden.
Der Block zeichnet eine Reihe von Stichmustern entweder in horizontale oder vertikale Richtung.
Über den if-Block wird jeweils festgelegt, ob mit einem Ober- oder Unterstich begonnen wird.
Schliesslich wird das ganze Programm für das Quadrat zusammengesetzt, indem der beschriebene Block zweimal aufgerufen und anschliessen noch ein Rahmen um das Bild (Vieleck) gezeichnet wird.
Bei der Programmierung des quadratischen Musters muss der Hauptblock zweimal mit Parametern für unterschiedliche Richtungen aufgerufen werden.
Die Programmierung des zufälligen Dreiecksmusters gestaltet sich ein weniger komplizierter, da dabei nicht nur drei Richtungen berücksichtigt werden müssen, sondern die Länge der einzelnen Stichfolgen laufend abnimmt.
Im Gegensatz zum Quadratmuster weisen die Stichfolgen beim Dreiecksmuster unterschiedliche Längen auf.
Ist der Block einmal programmiert, kann er aus dem Hauptprogramm von den unteren beiden Dreiecksecken aufgerufen werden, wobei die entsprechende Ausrichtung festgelegt werden muss.
Der Block zum Zeichnen der Stichfolgen muss beim Dreieck dreimal mit unterschiedlichen Winkeln aufgerufen werden.
Im Unterricht können in Abhängigkeit von der zu Verfügung stehenden Zeit unterschiedliche Aspekte in den Vordergrund rücken.
Kulturell-ästhetischer Aspekt
Ausgehend von kleinen Zeichnungen, die manuell ausgeführt werden, steht hier die Ästhetik und die Anwendung der Muster in der japanischen Kultur im Vordergrund. Das hier beschriebene Programm und das Original von Jens Mönig werden dann zur Generierung weiterer Muster verwendet, ohne dass dabei auf die Details der Programmierung eingegangen werden muss.
Mathematisch-technischer Aspekt
Ausgehend von der Stichfolge und deren binären Repräsentation wird die Programmierung schrittweise aufgebaut. Ob dabei die determinierte Variante von Jens Mönig oder die hier vorgestellte zufallsgesteuerte Version in den Fokus gerückt wird, ist eher nebensächlich. Bei entsprechender Ausstattung kann auch eine Umsetzung in TurtleStich in Betracht gezogen werden.
Informatischer Aspekt
Ausgehend von der Programmierung der Zufallsvariante können verschiedene Aspekte der Programmierung wie Unterfunktionen und Refaktorisierung die zentrale Rolle einnehmen, denn an die Programmierung des Zufallsprogrammes müssen sich die Schülerinnen und Schüler auf jeden Fall herantasten können. Inwieweit dies möglich ist, hängt von der Vorerfahrung und der zu Verfügung stehenden Zeit ab.
Das Beispiel der Sashiko-Muster zeigt sehr schön, wie wesentliche Aspekte der Informatik mit anderen Fächern unter ästhetischen Gesichtspunkten verknüpft werden können. Dabei greift das Beispiel in idealer Weise Hans Aeblis didaktische Forderung nach dem Wahren, Schönen und Guten im Unterricht auf.
Wenn man Snap! verwenden möchte, um wie bei Logo eine Figur auf den Bildschirm zu zeichnen, brauchen Anfänger eine Weile, um den Zusammenhang zwischen den einzelnen Befehlen und der Auswirkung auf die Bewegungen zu verstehen. In der Regel erarbeiten sie sich dieses Verständnis dann im „Versuch und Irrtum“-Verfahren, was nicht nur viel Zeit in Anspruch nimmt, sondern je nach Komplexität der Aufgabe auch das Lernen verhindert.
Eine Möglichkeit hier die Einstiegshürden zu senken, sind sogenannte Cheatsheets, also Zusammenfassungen der wichtigsten Blöcke, oder Programme Cards, kurze Programmbeispiele. Beide eignen sich hervorragend für den Unterricht. Leider ist aber das Dokumentieren von Befehlsblöcken und das Zusammenstellen solcher Programmieranleitungen aufwändig.
Animation als Dokumentation
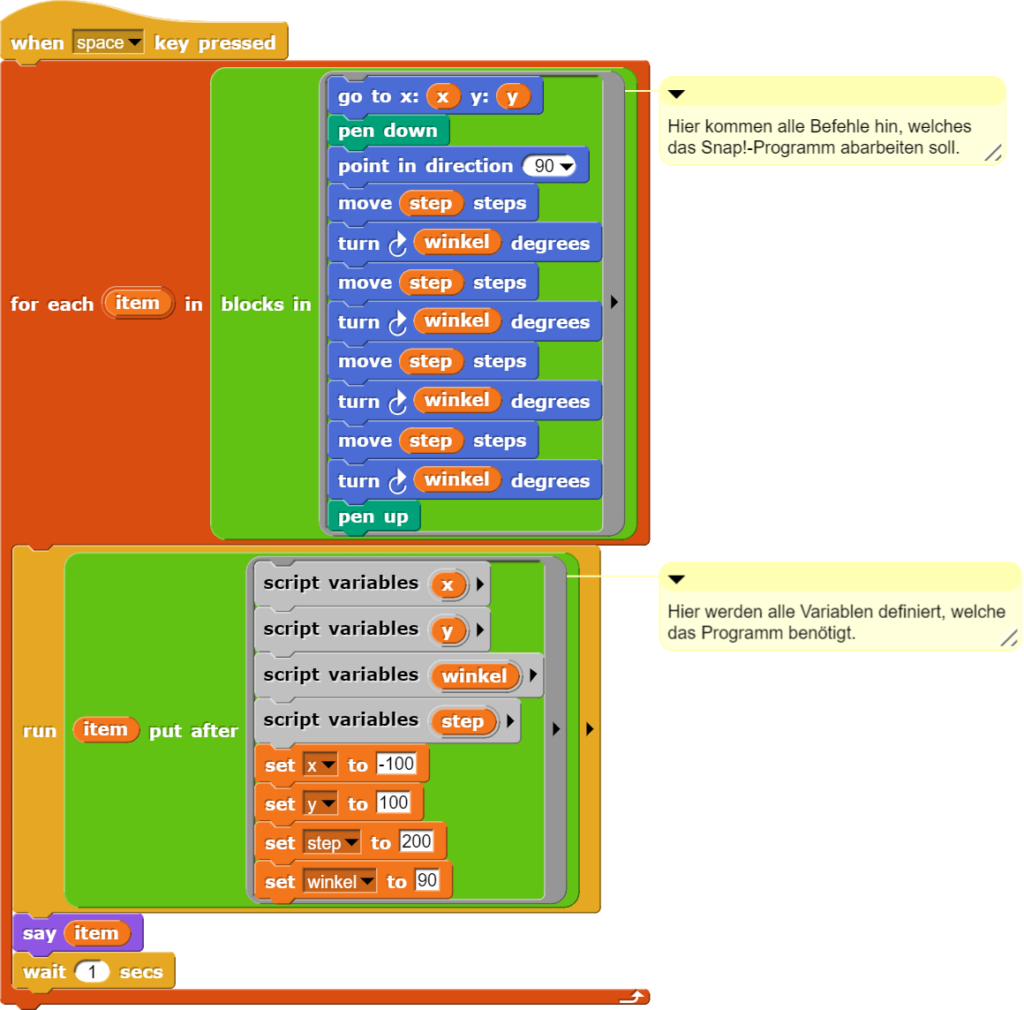
Für Snap! gibt es nun dank des Snap!-Nutzers pumpkinhead einige interessante neue Blöcke, die man zumindest für die Dokumentation einfacherer Programmieraufgaben verwenden kann. Dabei kann ein in Snap! geschriebenes Programm so ausgeführt werden, dass es gleichzeitig erklärt, welche Befehle es abarbeitet. Das Beispiel der Konstruktion eines Quadrats soll zeigen, wie dies aussieht.
Während Snap! ein Quadrat zeichnet, zeigt es, welche Befehle für jeden einzelnen Schritt benötigt werden.
In Snap! selbst setzt man folgende Blöcke dafür ein, um das Programm auszuführen.
Mit wenigen Blöcken kann eine Selbstdokumentation für Snap! erzeugt werden.
Die auszuführenden Blöcke werden zuerst als Liste abgespeichert und dann mit einem „for each“-Block schrittweise abgearbeitet. Ein Arbeitsschritt besteht darin, einen Befehl ausführen und ihn im Anschluss anzeigen zu lassen. Der „wait“-Block sorgt dafür, dass genügend Zeit für das Lesen der angezeigten Blöcke bleibt.
Wenn ein Programm (wie oben) Variablen enthält, muss man diese im Block „.. put after …“ noch einmal deklarieren, da die so ausgeführten Blöcke keinen direkten Zugriff auf die normalen Variablen haben. Damit geht auch die Einschränkung einher, dass die Werte von Variablen während der Ausführung des Scripts nicht geändert werden können, die Variablen werden also als Konstanten behandelt.
Snap! zeigt, wie man eine Figur zum Satz des Pythagoras zeichnen kann.
Die gezeigten Befehle dienen als Grundlage für einen rekursiven Block, mit dem ein sogenannten Pythagorasbaum gezeichnet werden kann.
Möchte man ein solches Beispiel nicht in Snap! direkt laufen lassen, kann man den Bildschirm mit einem geeigneten Programm aufzeichnen lassen und eine Videodatei zu Verfügung stellen oder aber die so erstellte Videodatei mit einem entsprechenden Webdienst in ein animiertes GIF umwandeln.
Ein einfaches Beispiel kann über den folgenden Link direkt in Snap! aufgerufen werden: Selbstdokumentation.
Anwendung im Unterricht
Im Unterricht kann das vorgestellte Verfahren auf zwei Arten verwendet werden. Einerseits wie beschrieben zur Dokumentation insbesondere von Bewegungsabläufen, andererseits kann die Lösung auch zum Finden von Fehlern in etwas längeren Programmen benutzt werden. Denn die Verknüpfung von schrittweiser Abarbeitung mit dem direkten Anzeigen des verantwortlichen Befehls nach der Ausführung, erlaubt eine Unmittelbarkeit, die sonst beim Programmieren kaum zu erleben ist. Falls Lernende diesen zweiten Weg beschreiten sollen, ist es von Vorteil, die entsprechende Umgebung vorzubereiten. Dazu gehört auch die Deklarierung allfälliger Variablen.
Mit dem Computer erzeugte Kunst auf der Basis von sich wiederholenden Elementen, eignet sich für den Einstieg in die Programmierung, weil diese vergleichsweise einfach programmiert werden können. Sobald aber etwas höhere Anforderungen an die Ästhetik dieser Werke gestellt werden, scheitern Schülerinnen und Schüler der Sekundarstufe I schnell an Details. Aus diesem Grund werden hier in Snap! geschriebene Blöcke vorgestellt, welche als Starthilfe gedacht sind und hoffentlich zu visuell ansprechenden Ergebnissen führen.
Die Grundidee
Die Grundidee solcher Kunstwerke lässt sich am besten anhand von Diagonalen innerhalb eines Quadrates veranschaulichen, wobei die Ausrichtung solcher Diagonalen zufällig ausgewählt werden soll. Obwohl das Beispiel sehr einfach ist, es gibt nur die beiden Elemente / und \ entstehen bei genügend Wiederholungen interessante Muster. Schon bei vier Feldern entstehen 16 = 2 x 2 x 2 x 2 Muster.
Alle Möglichkeiten bei einem 4×4-Feld wenn Diagonalen als Elemente eingesetzt werden.
Viele Grundelemente können sogar in vier Richtungen gedreht werden, wodurch die Anzahl der Möglichkeiten bei vier Feldern auf 4 x 4 x 4 x 4 = 256 ansteigt.
Einzelne Elemente
Beim Entwerfen einzelner Elemente, aus denen später das Raster aufgebaut wird, lohnt es sich, zuerst von Hand auf Papier zu arbeiten. So kann schnell ausprobiert werden, ob eine Wiederholung solcher Elemente zu einem interessanten Muster führt.
Hat man ein interessantes Muster gefunden, kann man dies in Snap! dank der Turtlegrafik mit wenigen Befehlen programmieren.
Mit wenigen Befehlen können alle Figuren, deren Teilelemente Geraden sind, programmiert werden.
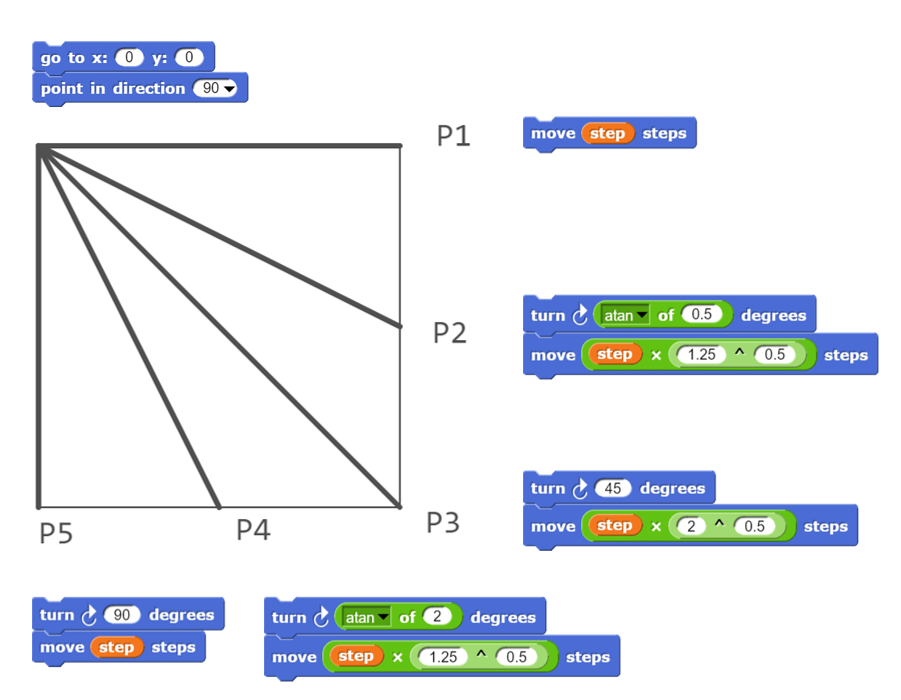
Schwierig ist allenfalls die Berechnung der Winkel und Streckenlängen für die einzelnen Teilelemente. Falls die Schülerinnen und Schüler beispielsweise den Satz des Pythagoras noch nicht kennen, kann man ihnen eine entsprechende Hilfe zu Verfügung stellen.
Diese Grafik erleichtert die korrekte Programmierung von Schrägen im Grundraster.
Ob die Besprechung von trigonometrischen Funktionen auf der Sekundarstufe I sinnvoll ist, hängt auch davon ab, wie viel Zeit zu Verfügung stehen. Zumindest die Berechnungen können die Lernenden aber durchführen, da die entsprechenden Funktionen auf den handelsüblichen Schultaschenrechnern zu Verfügung stehen.
Einpassen in ein Raster
Damit es später nicht zu Schwierigkeiten beim Einpassen der Elemente in ein Raster kommt, sollten von Anfang an Variablen für die entsprechenden Strecken in den Figuren verwendet werden. Ausserdem lohnt es sich, die einzelnen Befehlsschritte in einen eigenen Block zu verpacken. Am Beispiel der Diagonalen soll dies aufgezeigt werden:
Die Diagonale selbst, kann mit zwei Blöcken programmiert werden.
Für das Testen bereits vorhandener oder selbst geschriebener Figuren steht ein Block zu Verfügung mit dem man diese testen kann.
Die for-Schleife am Anfang des eigenen Blocks dreht die Figur in die zwei möglichen Positionen. Wenn es vier Positionen gibt, muss der Zufallszahlenblock entsprechend angepasst werden.
Damit der Block vor dem Einsatz in einem grösseren Raster überprüft werden kann, steht eine entsprechende Testumgebung zu Verfügung. Diese wird mit folgendem Block aufgerufen:
Dieser Block erlaubt es, einzelne Figuren bequem zu testen.
Beim Testen ist darauf zu achten, dass die Grösse der Quadratseite mit dem Parameter #1 übergeben wird. Die Grösse der Bildschirmausgabe kann mit size (verändert die Bühnengrösse) und border (verändert die Breite des Rahmens) entsprechend angepasst werden.
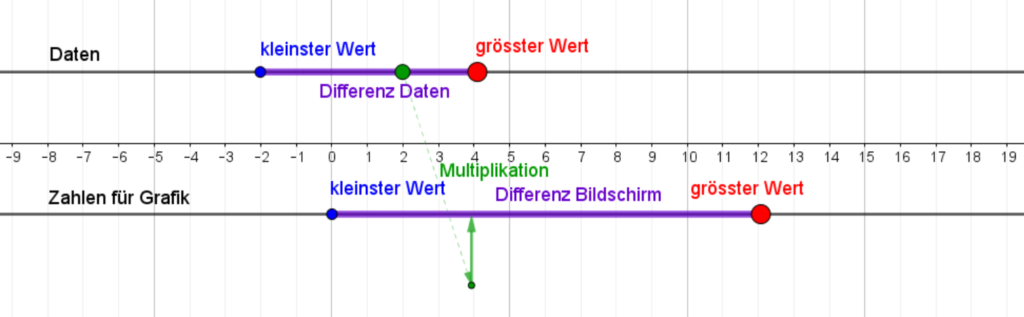
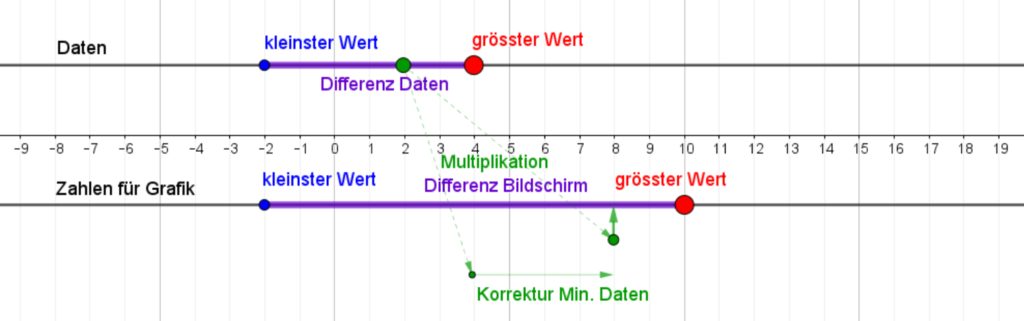
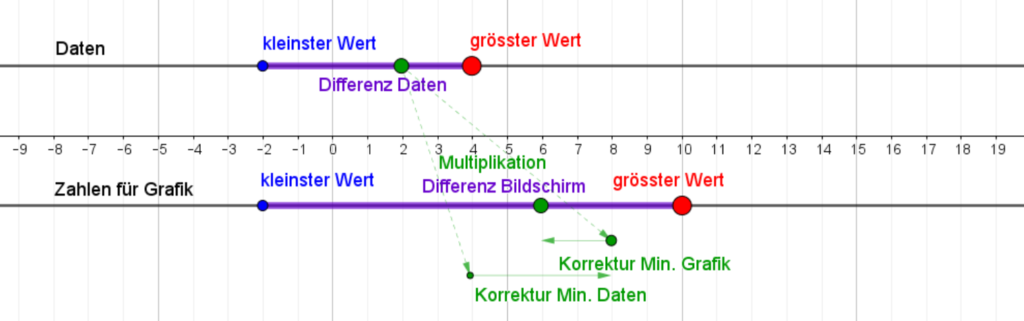
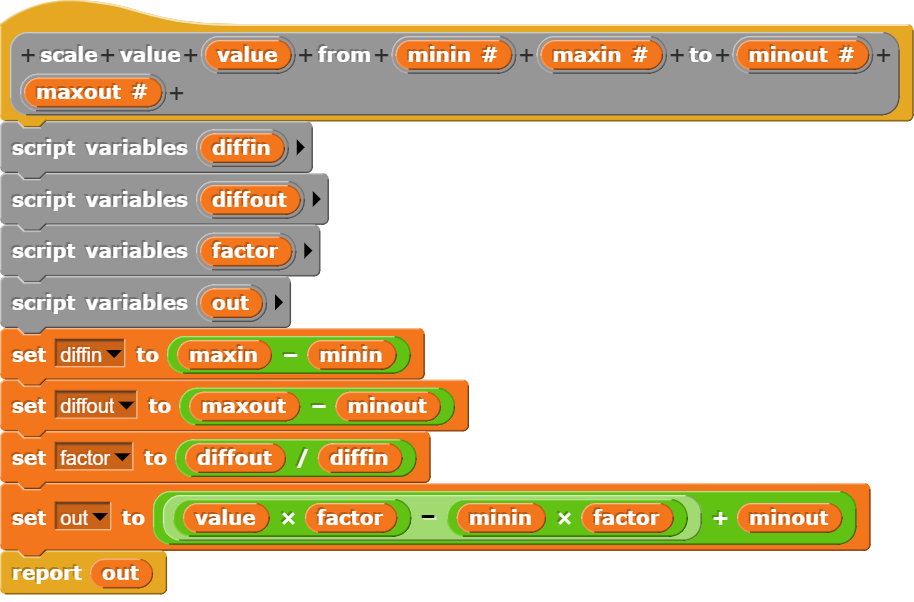
Funktioniert alles wie gewünscht, kann der getestete Block im Raster verwendet werden. Hierzu steht ebenfalls ein Block zu Verfügung, weil das richtige Setzen der Werte den Lernenden aufgrund des Koordinatensystems von Snap! oft Schwierigkeiten bereitet. Bei Snap! liegt der Nullpunkt nämlich in der Mitte des Bildschirms, was ein bequemes Arbeiten mit negativen Zahlen zulässt, im Falle eines Rasters für generative Kunst aber eher hinderlich ist.
Dieser Block übernimmt die Berechnung der Koordinaten für die einzelnen Teilflächen.
Dem Block muss die Anzahl der Quadrate in x- und y-Richtung und die Länge einer Quadratseite übergeben werden. Speichert man vorher die Dimensionen des Bildschirms und gibt an, wie viele Teilfelder man in die entsprechende Richtung haben möchte, werden die entsprechenden Werte (size and step) automatisch berechnet. Wie aus den gleichen Angaben für die x- und y-Dimension zu sehen ist, berechnet der Block im vorgestellten Programm jeweils ein quadratisches Kunstwerk.
Bei diesem Beispiel wurden 100 Diagonalen in jeweils einer der beiden möglichen Ausrichtungen gezeichnet.
Einfärben der Kunstwerke
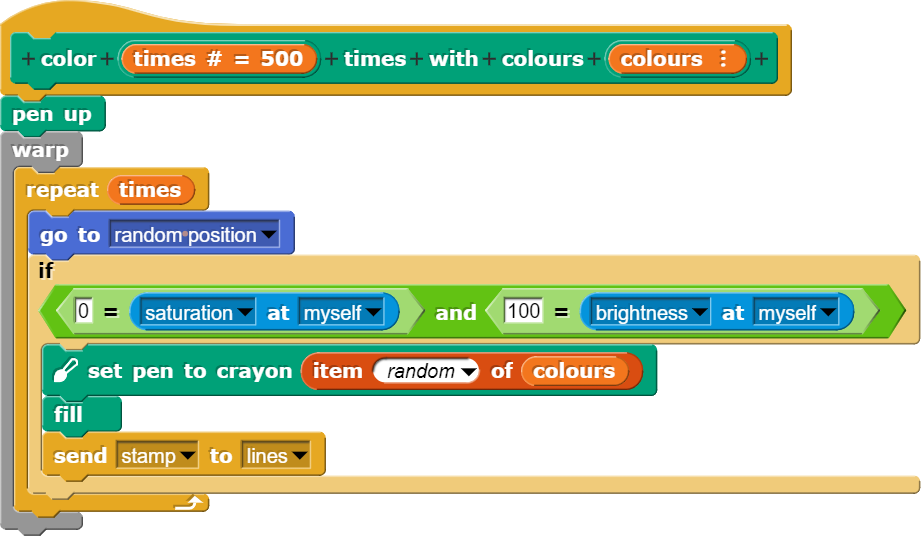
Da nur aus Linien bestehende Beispiele manchmal etwas schlicht wirken, können die erzeugten Bilder mit einem entsprechenden Befehl eingefärbt werden. Dazu springt der Block an eine beliebige Stelle im Bild und wenn der dortige Pixel weiss ist, wird mit dem fill-Block die Umgebung bis zur Begrenzung (schwarze Linien) ausgemalt.
Der Block färbt eine Teilelemente einer Zeichnung mit einer beliebigen Farbe aus einer gegebenen Farbpalette ein.
Beim Einfärben ist unbedingt darauf zu achten, dass das entsprechende Objekt (Sprite) vorher versteckt wird, sonst werden womöglich einzelne Bildteile falsch eingefärbt.
Das bereits vorgestellte Beispiel wurde mit den Farben aus einer entsprechenden Palette eingefärbt.
Der Baukasten
Aktuell können in Programm bereits 15 Grundelemente (mit den entsprechenden Drehungen) eingesetzt werden. Eine Übersicht der verschiedenen Elemente kann hier als PDF heruntergeladen werden:
Zwei weitere Beispiele sollen zeigen, was mit den vorgefertigten Elementen möglich ist.
Farbige Quadrate unterschiedlicher Grösse fügen sich zu einem Gesamtbild zusammen.
Bei diesem Beispiel wurde darauf verzichtet, das Bild nachträglich einzufärben, da der Befehl Nr. 4 bereits farbige Quadrate produziert.
Dieses Bild entstand durch das Weglassen von Teilstrecken in einem regelmässigen Muster.
Der Block Nr. 6 zeichnet Rhomben, deren Seiten zufallsgesteuert erzeugt werden. Je kleiner der Wert (hier: 0.7), desto mehr Lücken entstehen im Bild, wodurch grössere zusammenhängende Flächen erzeugt werden.
Kombination von Blöcken
Der „draw grid“-Block ist so programmiert, dass ihm auch mehrere Blöcke in einer Liste übergeben werden können. Pro Teilquadrat wird dann wieder jeweils einer dieser Blöcke zufällig ausgewählt. Damit erhöht sich die Vielfalt der mit dem Programm generierbaren Kunstwerke weit über die blosse Einzelverwendung der 15 vorgegebenen Blöcke. Während einige Kombinationen durch grosse zusammenhängende Flächen eher langweilig wirken, führen andere Kombinationen zu äusserst interessanten unregelmässigen Mustern.
Kombination der Blöcke 6 (mit einer zufälligen Wahrscheinlichkeit zwischen 0.7 und 1.0) und 15.
Während der Block 6 die schon erwähnten Rhomben mit fehlenden Seiten generiert, erzeugt der Block 15 eine Pfeilfigur.
Für dieses Bild wurden die Blöcke 5 (mit einer zufälligen Wahrscheinlichkeit zwischen 0.7 und 1.0) und 10 kombiniert.
Das Programm
Das Programm kann unter folgendem Link aufgerufen werden: Repeating Elements. Wird es über die grüne Flagge gestartet, generiert es automatisch ein Diagonalenbild. Möchte man weitere Beispiele erzeugen, muss man in den Editiermodus wechseln. Dort präsentiert das Programm 6 verschiedene Objekte:
Demonstration erzeugt ein Diagonalenbild, wobei die Anzahl der Felder über „set step“ und die Auflösung der Grafik über „set value: Stage size“ gesteuert werden kann.
Experiments erlaubt die Durchführung eigener Experimente, wobei einer der 15 vorgefertigten Blöcke aus dem „Motion“-Bereich verwendet werden kann.
Testing ermöglicht wie schon beschrieben das Ausprobieren neuer Blöcke, um sicherzustellen, dass diese wunschgemäss funktionieren.
Blocks erklärt die Verwendung einiger der im Programm verwendeten Blöcke.
Tricks gibt einige Tipps zur Verwendung des Programms.
Examples erzeugt zufallsgesteuert ein Kunstwerk, indem es bis zu vier verschiedene Elemente kombiniert. Welche Elemente jeweils verwendet wurden, kann man über die Variable „elements in use“ abfragen.
Per Zufall wurden die Blöcke 6, 9 und 13 ausgewählt, um dieses Bild zu erzeugen.
Dieser Beitrag ist ein Entwurf zum Workshop „Zahlen, Daten und Medien“ am Open Education Day vom 24. April 2021. Er dient als Arbeitsgrundlage und Dokumentation und wird nach der Durchführung noch einmal überarbeitet.
Ausschreibung des Workshops
Mit Hilfe der blockbasierten Programmierumgebung Snap! (https://snap.berkeley.edu) lernen die Teilnehmenden Möglichkeiten kennen, wie informatische Kenntnisse in den Bereichen Zahlen, Daten (Visualisierungen) und Medien (Musik, Grafik und Video) mit Lernenden der Sekundarstufe I auf eine motivierende Weise umgesetzt werden können (siehe auch https://gigers.com/blog/?s=snap). Die vorgestellten Beispiele können von den Teilnehmenden ausprobiert und erweitert werden, dabei sollen theoretische Kenntnisse, praktische Anwendung und kreative Umsetzung verknüpft werden.
Snap! ist eine Programmiersprache, welche nach dem Prinzip „low floor – high ceiling“ entwickelt wurde, damit ermöglicht sie einerseits einen leichten Einstieg, erlaubt aber auch die Umsetzung fortgeschrittener Programmiertechniken. In den USA wird Snap! u.a. im Leistungskurs „The Beauty and Joy of Computing“ (https://bjc.edc.org) eingesetzt und mit „Informatik mit Snap!“ (http://ddi-mod.uni-goettingen.de/InformatikMitSnap.pdf) existiert auch ein deutsches Lehrmittel für die Hochschulstufe.
Planung für den Workshop
Geplant ist eine Aufteilung des Workshops in drei Abschnitte:
Zahlen und Daten
Am Beispiel eines Datensatzes wird gezeigt, wie Informationen in Snap! visualisiert werden können. Wenn möglich werden noch weitere Beispiele gezeigt.
Töne erzeugen und Geräusche visualisieren
Aus ein paar Zahlen entstehen Töne und über das Mikrofon werden Geräusche visualisiert.
Grundlagen der Bildbearbeitung
Bilder sagen mehr als tausend Worte und bestehen meist aus noch mehr Zahlen. Diese werden mit den in den ersten beiden Teilen erarbeiteten Techniken bearbeitet.
Wie viel davon in den 90 Minuten Workshop umgesetzt werden kann, wird sich zeigen. Alle Beispiele werden aber in den folgenden Abschnitten detailliert dokumentiert.
Teil 1: Zahlen und Daten
Am Beispiel eines Datensatzes zu Wolkenkratzern (via Corgis-Edu) wird gezeigt, wie man mit vorhandenen und selbstgeschriebenen Blöcken (stehen zu Verfügung) einen Blick in grössere Datensätze werfen kann.
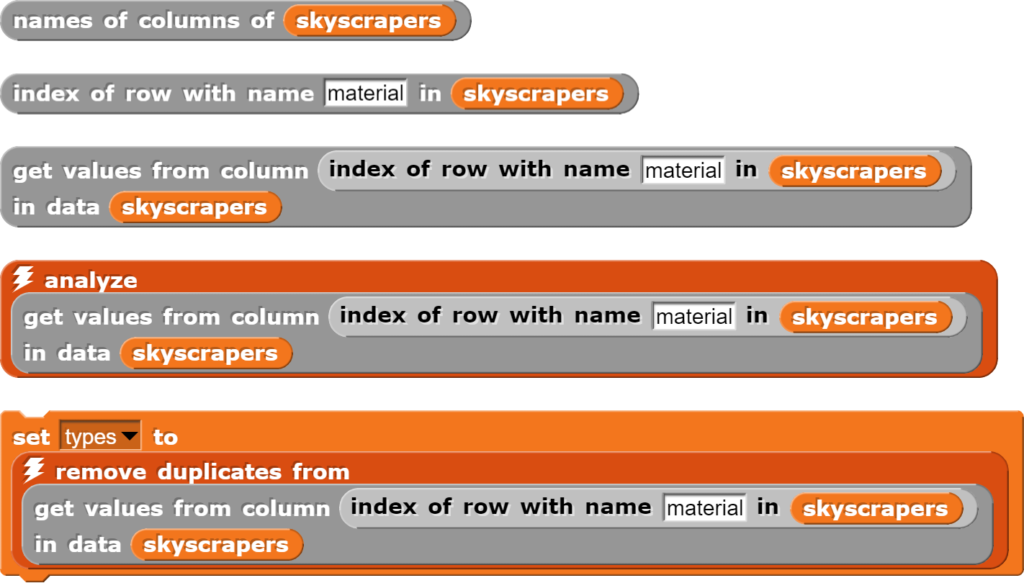
Mit einigen Blöcken wird der Datensatz darauf untersucht, aus welchen Materialien die Wolkenkratzer gebaut wurden und wie häufig die entsprechenden Materialien zum Einsatz kamen. Dazu werden folgende Blöcke verwendet:
Mit diesen Befehlen können die Wolkenkratzerdaten auf die Baumaterialien der Gebäude hin analysiert werden.
Bei den grauen Blöcken handelt es sich um zusätzliche Blöcke, die orangen Blöcke stehen nach dem Import der Bibliotheken „Frequency Distribution Analysis“ und „List utilities“ zu Verfügung.
Im Workshop dient diese erste Übung auch dazu, mit ersten Merkmalen der Snap!-Entwicklungsumgebung vertraut zu werden. Mehr dazu ist im Beitrag „Interaktive Erklärungen mit H5P Image Hotspots“ zu erfahren.
Im nächsten Schritt geht es darum, die Wolkenkratzer auf einer Weltkarte zu visualisieren. Die Programmierung dieses Beispiels erfolgt in den folgenden Schritten:
Weltkarte als Hintergrund festlegen;
Den eigenen Standort anzeigen;
Wolkenkratzer auf der Weltkarte eintragen;
Einzelne Wolkenkratzer gestalten.
Im Gegensatz zu den im Workshop durchgeführten „Live Coding“ werden hier bei der schriftlichen Dokumentation schon die fertigen Blöcke dargestellt. Auf einen schrittweisen Aufbau der einzelnen Befehlsblöcke wird hier also verzichtet.
Weltkarte als Hintergrund festlegen
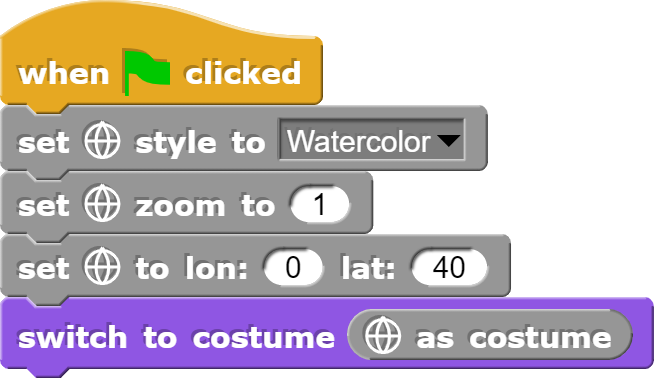
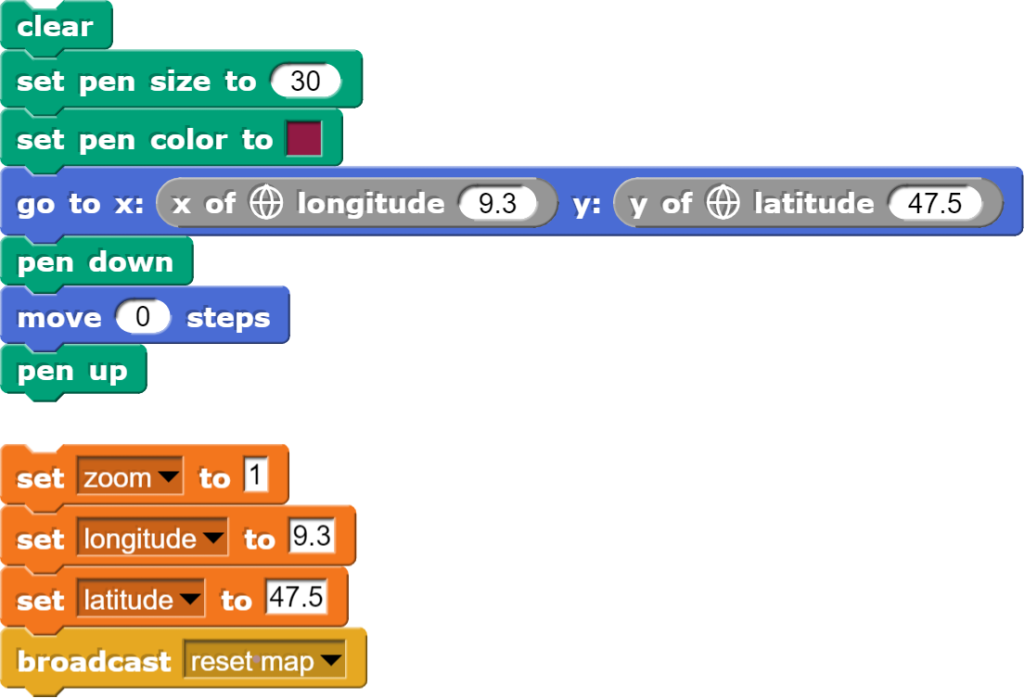
Die Befehle zur Darstellung der Weltkarte werden aus der Bibliothek „World Map“ importiert. Anschliessend kann die Weltkarte auf der Bühne dargestellt werden.
Um eine Karte darzustellen, müssen die entsprechenden Parameter gesetzt werden.
Folgende Parameter können für die Karte gesetzt werden:
style: bestimmt das Aussehen der Karte;
zoom: bestimmt, wie gross der Ausschnitt der gezeigten Karte ist, wobei bei 0 die ganze Welt und bei 15 die Nachbarschaft gezeigt werden;
set to: bestimmt das Zentrum der Karte (die Voreinstellung 0, 0 ist meistens nicht optimal)
Anschliessend muss sich die Bühne mit „switch to costume“ die entsprechende Karte noch überwerfen.
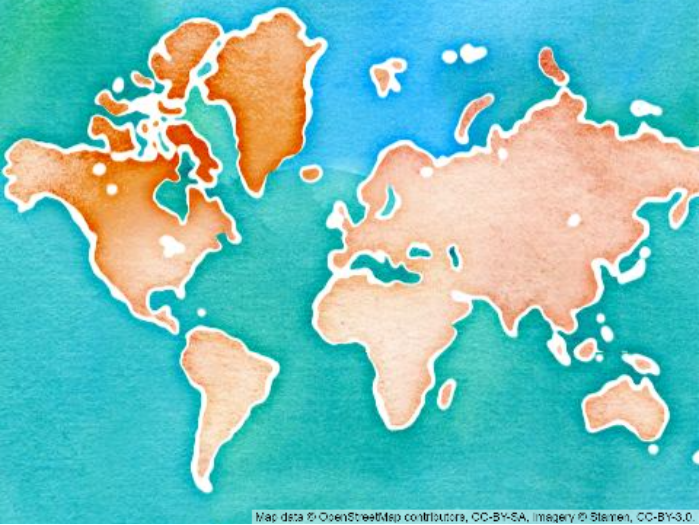
Das Setzen dieser Blöcke belohnt einem mit einem Hintergrund, der etwa so aussieht:
Das Beispiel zeigt den Stil „watercolor“.
Mehr zu den Möglichkeiten der Bibliothek „World Map“ ist im Beitrag „Landkarten mit Snap!“ beschrieben.
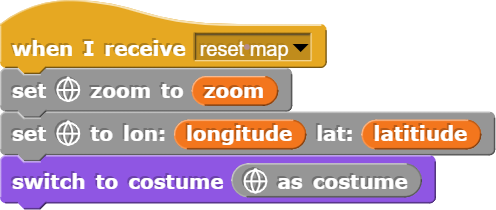
Damit das Programm letztlich funktioniert, muss später noch folgender Block hinzugefügt werden:
Diese Befehle sorgen dafür, dass das Aussehen der Karte von einem anderen Objekt aus gesteuert werden kann.
Damit kann die Karte auf den Befehl von anderen Objekten hin angepasst werden, wobei hier das Werkzeug der Mitteilungen verwendet wird. Bei komplexeren Programmen können damit Abläufe einfach gesteuert werden.
Das ist aber erst möglich, nachdem der nächste Teil des Programms geschrieben wurde.
Den eigenen Standort anzeigen
Damit der eigene Standort auf der Karte angezeigt werden müssen erst einmal die entsprechenden Koordinaten (Länge und Breite) bekannt sein. Am schnellsten findet man diese mit Google Maps, indem man auf der Karte am gewünschten Ort einen Rechtsklick mit der Maus ausführt. Dabei muss man allerdings beachten, dass die Reihenfolge bei Google Maps und Snap! nicht gleich ist.
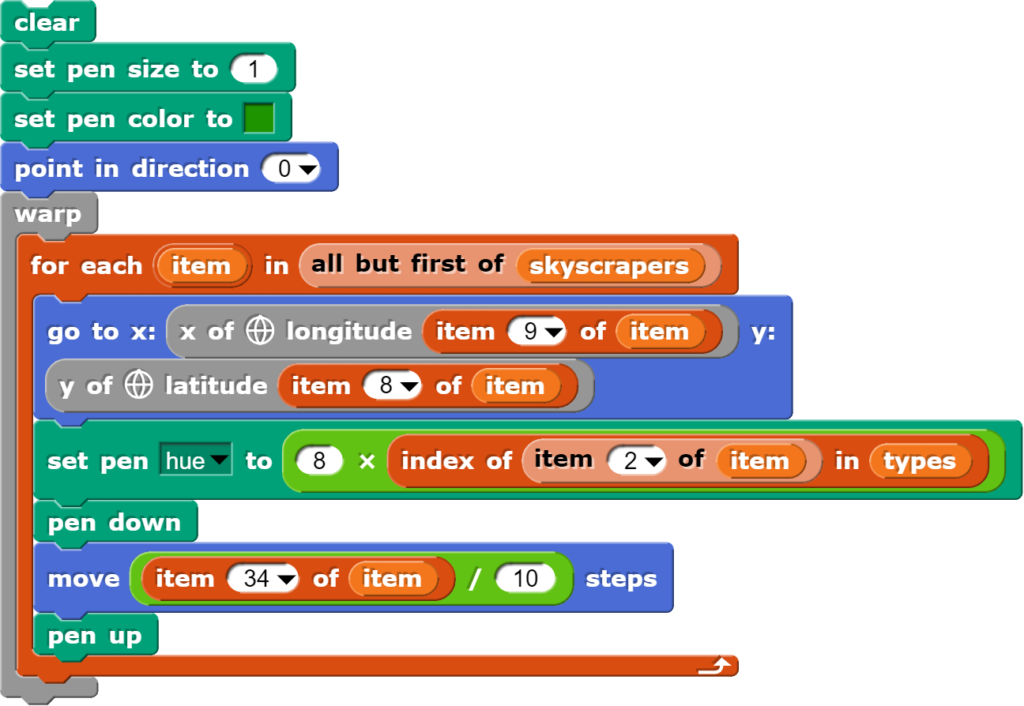
Den eigenen Standort, kann man mit den Blöcken „x of longitude“ und „y of latitude“ auf der Karte eintragen.
Die oben abgebildeten Blöcke werden nicht mehr im Bühnenbereich ausgeführt, sondern in einem eigenen Objekt.
Dabei werden folgende Befehle abgearbeitet:
den Bildschirm löschen;
die Stiftdicke auf 30 setzen;
zur gewünschten Koordinate gehen;
den Stift auf das Papier setzen;
einen Kreis zeichnen;
den Stift von Papier abheben.
Die unteren vier Blöcke dienen dazu den Ausschnitt der Karte anzupassen, denn wenn man in der Schweiz lebt, ist der Standort auf einer Weltkarte nicht besonders aussagekräftig. Je nach Genauigkeit der eingegebenen Koordinaten kann man den eigenen Standort so auch metergenau auf der Karte eintragen lassen und die nähere Nachbarschaft virtuell bewundern.
Wolkenkratzer auf der Karte eintragen
Während bei Menschen bei mehrfacher Ausführung der gleichen Tätigkeit schnell einmal Langeweile auftauchen kann, sind solche repetitive Aufgaben das Spezialgebiet von Computern. Und deshalb gilt hier: Was einmal gelungen ist, kann nun viele Male ausgeführt werden.
Für die Darstellung des Wolkenkratzers werden im Wesentlichen die gleichen Befehle benötigt, wie bei der Darstellung eines einzelnen Standorts
Im Wesentlichen werden hier die gleichen Befehle wie bei der Eintragung des Einzelstandorts verwendet, nur wird jetzt mit einer „forEach“-Schleife durch eine Liste iteriert. Die etwas komplexeren Befehle ergeben sich aus der von den Eigenschaften der einzelnen Objekte abhängigen unterschiedlichen Darstellung der Wolkenkratzer auf der Karte.
Einzelne Wolkenkratzer gestalten
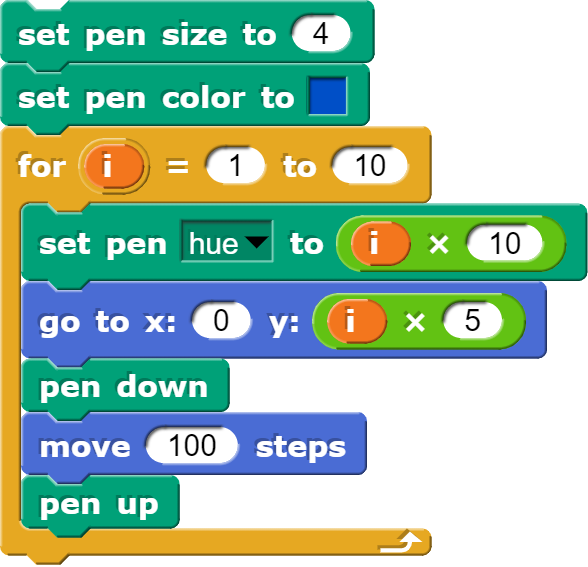
Um insbesondere die Farbgebung noch etwas besser zu verstehen, lohnt es sich auch hier, zuerst wieder einige Experimente durchzuführen. Die folgenden Blöcke leisten genau dies:
Mit diesen Blöcken können unterschiedliche Farbtöne erzeugt werden.
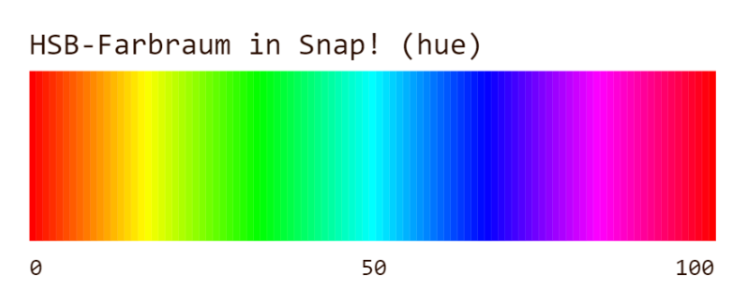
Um die Farbe anzupassen, kommt eine Variante des HSV-Farbmodels zum Einsatz, wobei mit dem H-Wert (hue) der Farbwert selbst beeinflusst wird. In Snap! wird dafür ein Bereich von 0 bis 100 verwendet.
Mit den entsprechenden Parametern können Regenbogenfarben erzeugt werden.
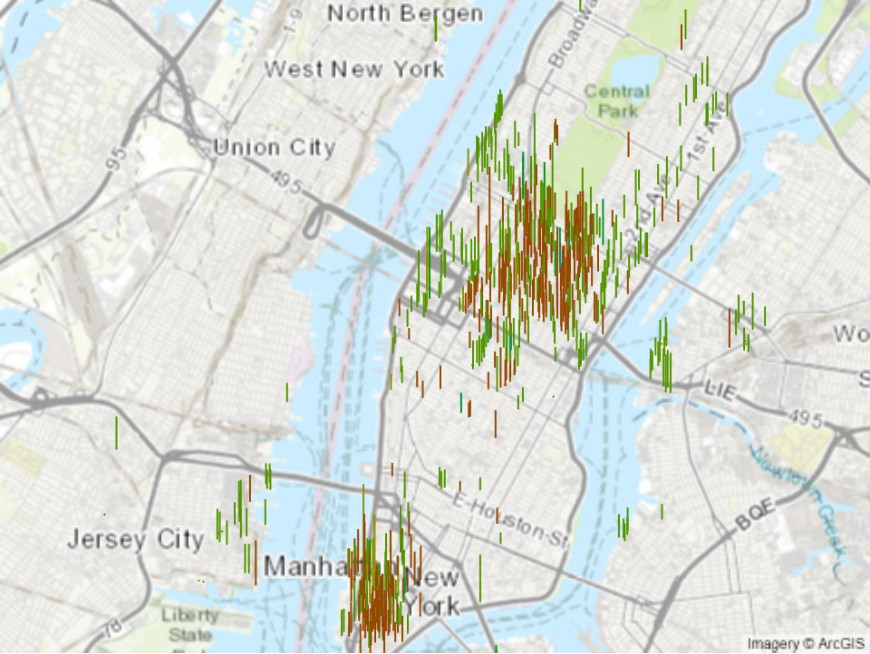
Hat man die Koordinaten für die Karten entsprechend eingestellt, kann man sich nur beispielsweise die Wolkenkratzer in New York anzeigen lassen.
Die im Datensatz enthaltenen Wolkenkratzer werden gemäss den vorgenommenen Einstellungen angezeigt.
Weitere Beispiele für Visualisierungen
Ohne weiter auf die Programmierung einzugehen, sollen hier noch die Resultate weiterer Visualisierungen gezeigt werden, die mit Snap? erzeugt wurden. Siehe dazu auch „Höhenmodell mit Snap„.
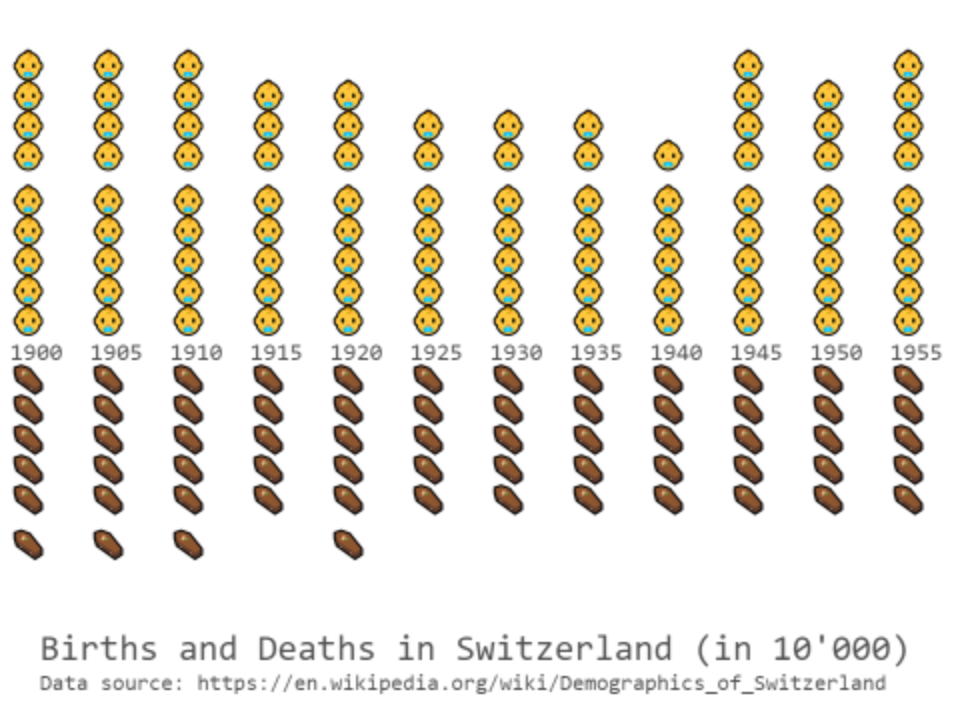
Die Grafik zeigt an, wie viele Personen in einem bestimmten Zeitraum jeweils geboren wurden oder gestorben sind.
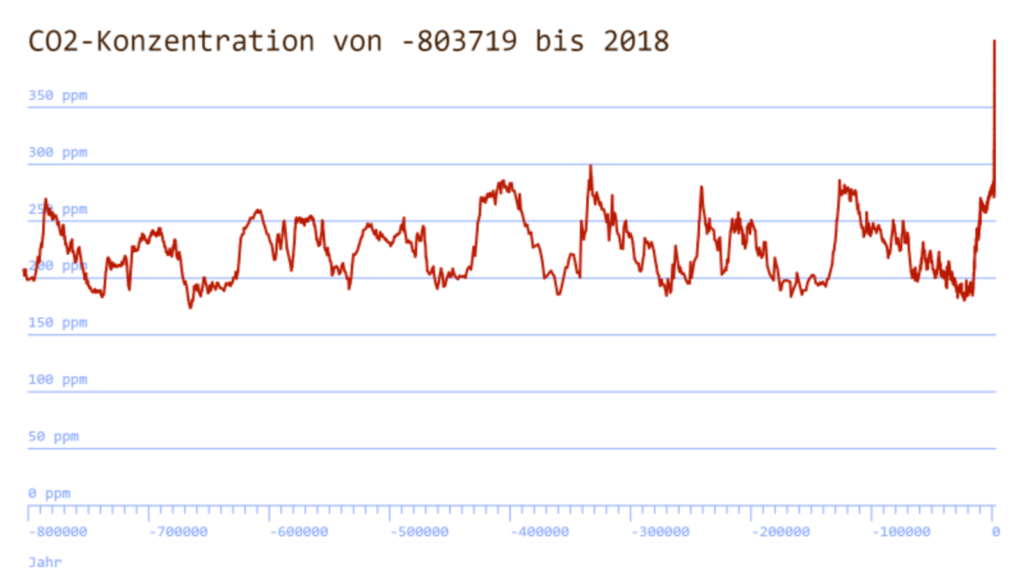
Die CO2-Konzentration in der Atmosphäre wird über die letzten rund 800’000 Jahre aufgetragen. Der rasante Anstieg in den letzten Jahren ist am rechten Rand der Grafik klar zu erkennen.
Es kann sich aber auch lohnen, zusammen mit den Lernenden selbst Daten zu erheben, z.B. zum Schulweg, Medienkonsum etc.
Musikalische Experimente mit Snap!
In diesem Teil des Workshops wird zuerst gezeigt, wie aus Zahlen Töne entstehen können und dann soll das Mikrofon zum Einsatz kommen, um Geräusche zu visualisieren.
Von der Zahl zum Ton
In Snap! werden Musikdateien als Listen mit Zahlen zwischen -1 und 1 repräsentiert, wobei pro Sekunde in der Regel mehr als 40’000 Zahlen benötigt werden. Im Gegensatz zu den im Teil „Zahlen und Daten“ verwendeten Daten des Workshops, sind die Datensätze nun zwar einfacher strukturiert, dafür aber wesentlich grösser.
In einem ersten Schritt soll untersucht werden, was passiert, wenn einfach genügend viele Zufallszahlen erzeugt und diese dann abgespielt werden.
Da die Zahlen völlig zufällig erzeugt werden, entsteht ein sogenanntes Weisses Rauschen.
Das entstehende Weisse Rauschen unterscheidet sich von einem Ton dadurch, dass keinerlei Ordnung zu erkennen ist. Visualisieren lässt sich dies mit einem Block aus der Bibliothek „Audio Comp“.
Der Block bietet eine einfache Möglichkeit, einen Blick in Audiodateien zu werfen.
Ordnung kann man auch als Wiederholung von bestimmten Mustern verstehen. Aus der Unordnung entsteht also Ordnung, indem wir einen kleinen Teil der Unordnung mehrfach wiederholen.
Die folgenden Befehle zeigen die Schritte auf, die zum Ziel führen.
Mit einer Variablen und wenigen Befehlen bringt man durch Wiederholung Ordnung in das Chaos. Diese Ordnung ist sowohl hör- als auch sichtbar.
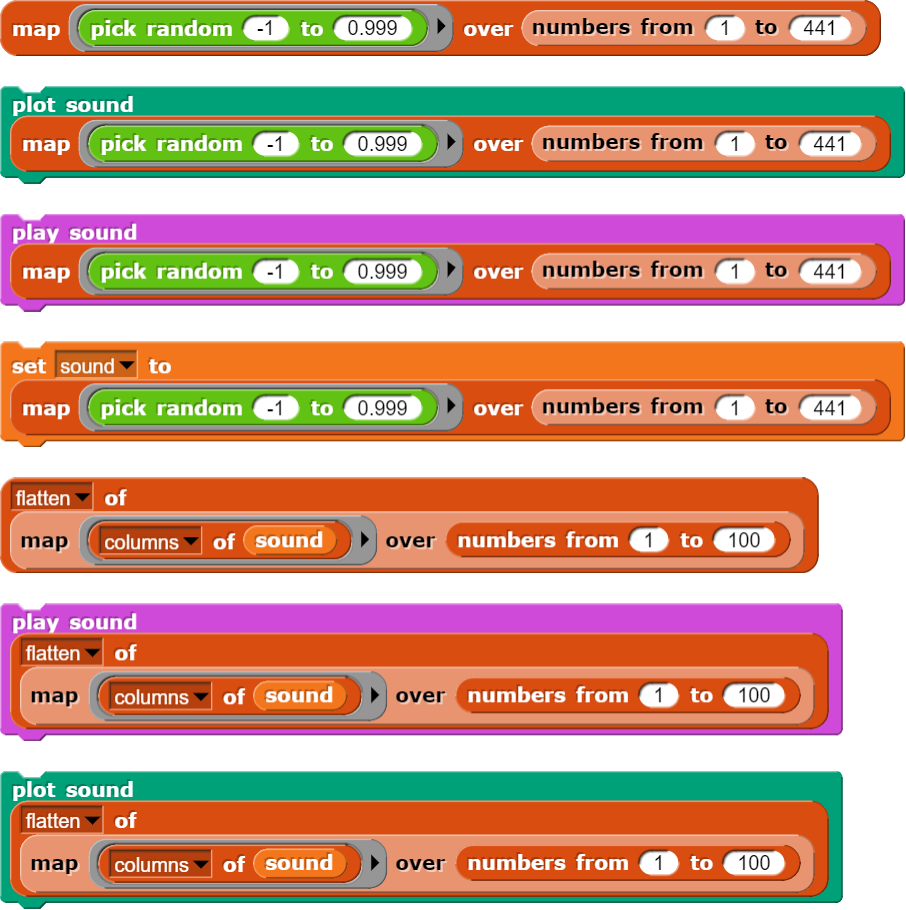
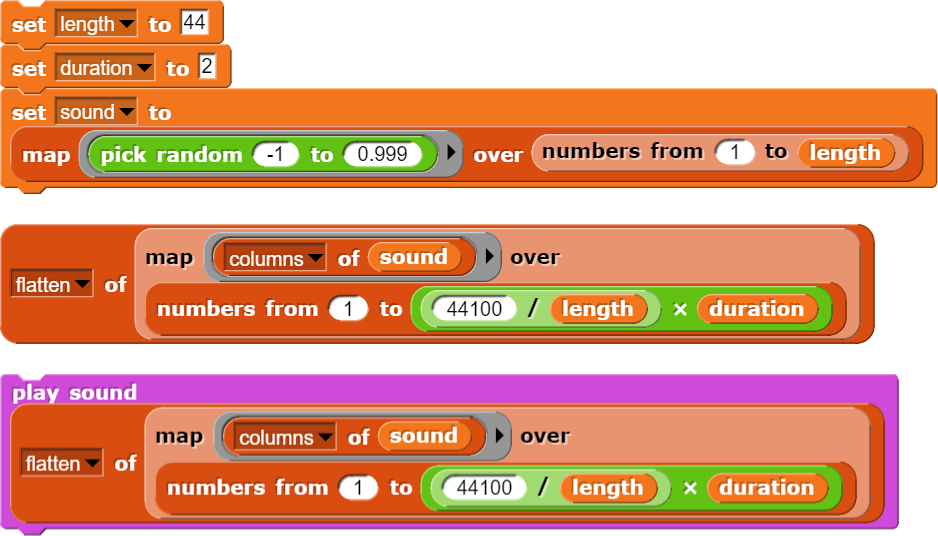
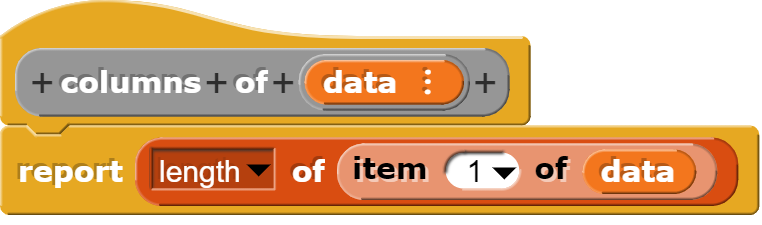
Der Ablauf wird in den oben gezeigten Blöcken wieder verdichtet dargestellt. Im Wesentlichen wird aber einfach ein Zahlenblock von 441 Zahlen 100-mal wiederholt. Die Blöcke „columns of“ und „flatten of“ werden nur benötigt, damit Snap! jeweils eine Liste im erwarteten Format vorfindet.
Nachdem es gelungen ist, einen äusserst reichen Ton zu generieren, kann man sich noch Gedanken darüber machen, wie die Tonhöhe und Tondauer angepasst werden können. Die Tondauer wird einfach durch die Anzahl aller Zahlen bestimmt und diese wiederum ist abhängig von der Länge des „Chaos“ und der Anzahl der Repetitionen. Wenn also die Zahl der Repetitionen vergrössert oder verkürzt wird, verändert sich auch die Tondauer.
Für die Tonhöhe ist die Zahl der Repetitionen innerhalb eines Zeitintervals (beispielsweise in Hertz gemessen) ausschlaggebend und diese wird durch die Länge des „Chaos“ bestimmt.
Wenn also in der „sound“-Variable nur wenige Zahlen gespeichert werden, dann führt dies innerhalb einer Sekunde zu vielen Wiederholungen und damit zu einer grossen Frequenz und einem hohen Ton.
Die Tonhöhe und -dauer kann mittels grundlegender Arithmetik gesteuert werden.
Damit ist es nun möglich, Töne beliebiger Länge und Frequenz zu erzeugen. Allerdings ist die Nutzung noch nicht besonders komfortabel. In einem nächsten Schritt müsste die Schnittstelle für die Benutzer durch Abstraktion vereinfacht werden. Aus Zeitgründen wird darauf im Workshop aber verzichtet, denn nun sollen mit dem Mikrofon gemessene Geräusche visualisiert werden.
Geräusche Visualisieren
Damit die Aufnahme mit einem Mikrofon in Snap! gelingt, muss die Aufnahme über die Webseite im Browser erlaubt werden. Da die entsprechenden Schritte sich von Browser zu Browser unterscheiden, sucht man bei Problemen am besten mit einer Suchmaschine nach einer entsprechenden Anleitung. Dabei helfen die Begriffe „Mikrofon“, „Browser“ und „erlauben“, „zulassen“ oder „freigeben“.
Ob das Mikrofon in Snap! wie gewünscht funktioniert, kann man mit folgendem kleinen Programm überprüfen:
Dieses Programm überprüft laufend das Eingangssignal des Mikrofons.
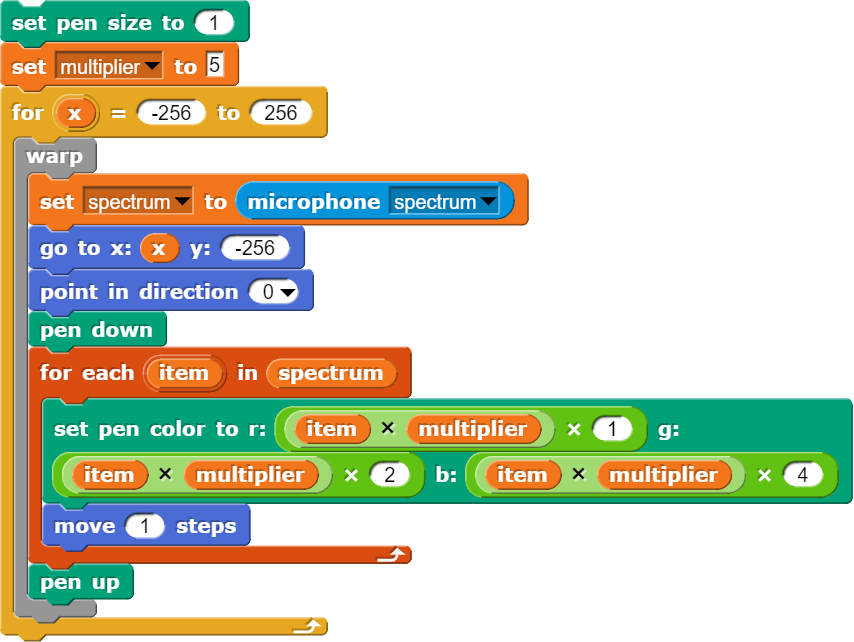
Der „microphone“-Block kann ganz unterschiedliche Informationen zurückliefern. Damit ist es beispielweise möglich, mit wenigen Befehlen ein Spektrum zu erzeugen, wobei hier wieder das fertige Programm abgebildet wird.
In Snap! lassen sich mit wenigen Befehlen ein Audiospektrum erzeugen.
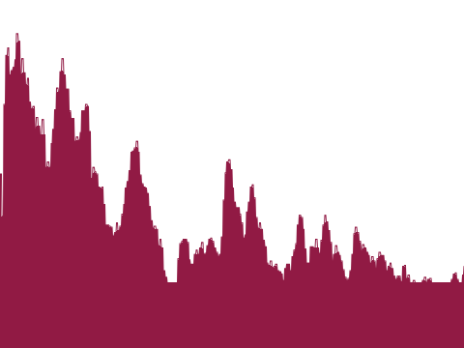
Dieses so programmierte Spektrum kann nun benutzt werden, um herauszufinden, wie der Klang verschiedener Instrumente oder aber die Vokalfärbung bei der menschlichen Stimme zustande kommt. Bei den sichtbar werdenden Spitzen im rechten Bereich des Spektrums handelt es sich um Obertöne, die verantwortlich für die Klangfarbe sind.
Das Spektrum veranschaulicht den Klang einer nasalen menschlichen Stimme.
Das gleiche Phänomen konnte man schon aus den mithilfe von Zufallszahlen generierten Tönen erleben, auch diese verdanken ihre Klangfarbe dem Obertonreichtum.
Sonagramm
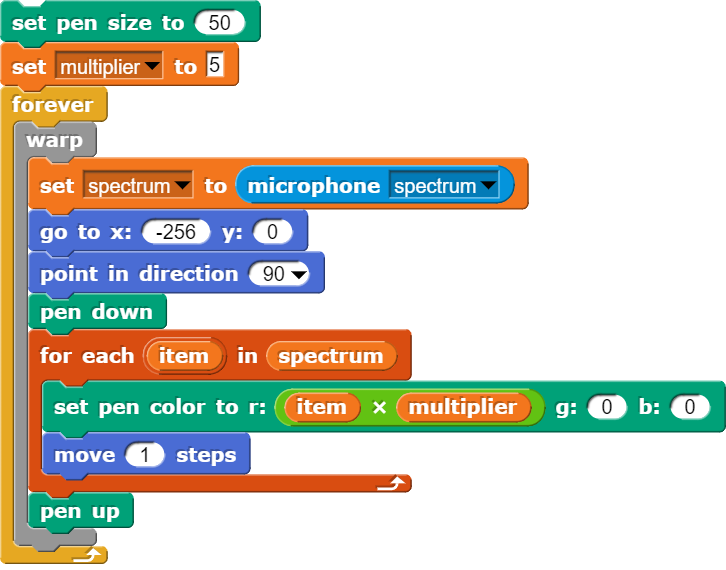
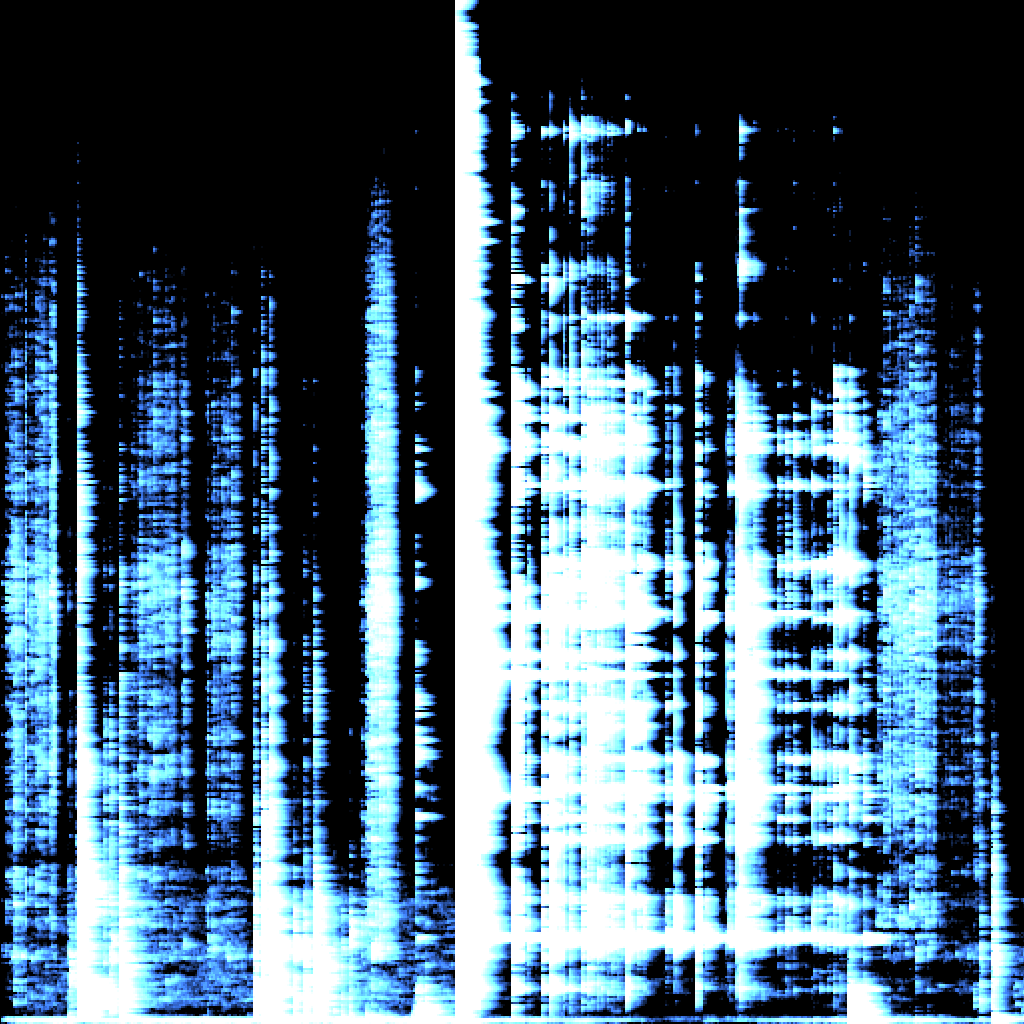
Das Spektrum zeigt immer nur eine Momentaufnahme. Wenn man die Daten auch über einen längeren Zeitraum aufzeichnen möchte, eignet sich dafür das Sonagramm. Dort werden die Lautstärken der einzelnen Frequenzen nicht mehr als Balken dargestellt, sondern in Farbwerte umgesetzt.
Das Programm kodiert die Schallintensität in den verschiedenen Frequenzbereichen farblich.Hohe Schallwerte werden durch hellere Farben dargestellt.
Solche Farbstreifen kann man nun um 90° drehen, schmaler gestalten und nacheinander aufzeichnen. Dazu muss das bisher bestehende Programm umgeschrieben werden.
Im Programm werden die Signale des Mikrofons für die Farbkanäle mit unterschiedlichen Werten multipliziert.
Da der „microphone“-Block jeweils 512 Werte liefert, lohnt es sich, die Ausgabegrösse der Bühne noch anzupassen. Dies funktioniert über die die Einstellungen der Snap!-Umgebung.
Das Sonagramm bildet das akustische Geschehen über einen bestimmten Zeitraum ab.
Grundlagen der Bildbearbeitung
Im dritten Teil des Workshops geht es um die Grundlagen der Bildbearbeitung. Bei hilft der Umstand, dass auch Grafiken in Snap! nur aus Zahlen bestehen. Für die folgenden Schritte kann entweder ein eigenes Bild verwendet werden, welches man einfach auf die Oberfläche zieht oder man steigt über die zu Verfügung gestellte Datei ein.
Snap! verfügt mit den Hyperblocks über ein sehr mächtiges Werkzeug, um grosse Datenmengen effizient zu bearbeiten. Hyperblocks erlauben es nämlich, eine arithmetische Funktion über alle Elemente einer Liste auszuführen, ohne dass dafür erste eine Schleife programmiert werden muss.
Die einzelnen Pixel jedes Farbkanals können mit vorhandenen Snap!-Befehlen schnell bearbeitet werden.
Mit den Hyperblocks und dem schon von den Audiodateien bekannten map-Block können bereits verschiedene Grafikfilter programmiert werden.
Den Zufall einbeziehen
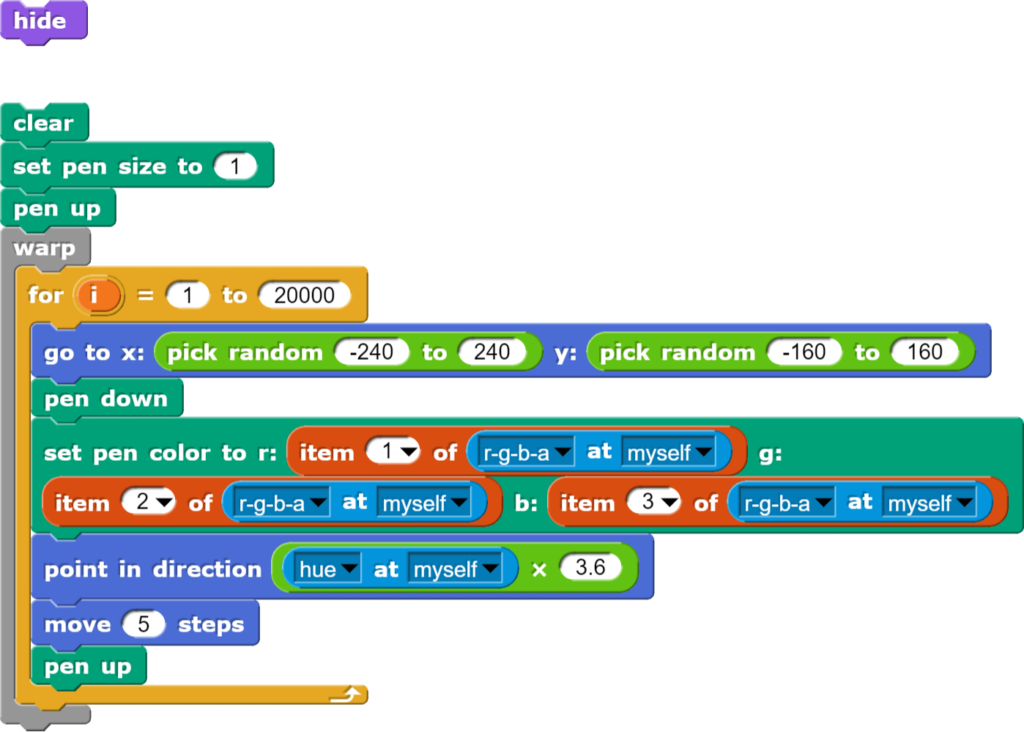
Im letzten Teil zur Grafikbearbeitung wird ein Wechsel von Berechnungen hin zur Arbeit mit dem Zufall vollzogen. Gleichzeitig erfolgt ein Wechsel von der Zahlen- auf die Bildebene. Damit wird gezeigt, dass bei Snap! unterschiedliche Zugänge zu einem Thema möglich sind.
Als Grundlage dient wieder das Katzenbild. Dieses soll in ein impressionistisches Gemälde umgestaltet werden, indem an zufälligen Orten im Bild der Farbwert ausgelesen und dann an der gleichen Stelle ein Farbklecks gemalt wird.
Auch hier wird wieder die Endfassung gezeigt, welche im Workshop schrittweise mit verschiedenen Varianten aufgebaut wird.
Das Programm zaubert aus einem Foto ein Kunstwerk mit interessanten Effekten.
Ursprünglich hatten sich etwa 25 Personen zum Workshop angemeldet. Die meisten äussersten sich während des Workshops weder schriftlich noch mündlich. Wer sich meldete, gab an, noch über wenig bis keine Erfahrung mit Snap! zu verfügen. Am Schluss des Workshops gaben vier Teilnehmende schriftlich an, sie könnten sich vorstellen, Snap! im Unterricht zu verwenden.
Die Befürchtung, zu wenig Material dokumentiert zu haben, erfüllte sich nicht. Im Gegenteil: Insgesamt konnte aus Zeitgründen nur etwa die Hälfte der geplanten Beispiele demonstriert werden.
Nachtrag vom 11. Mai 2021: Die Organisatoren des Open Education Days haben die Videoaufzeichnung online gestellt.
Weitere Ressourcen rund um Snap!
Erste Anlaufstelle zu allen Fragen rund um Snap! ist die offizielle Webseite.
Auf der offiziellen Webseite werden Beispiele zur Programmierung mit Snap! vorgestellt. Allfällige Fragen stellt man über ein Forum an die engagierte und hilfsbereite Snap!-Gemeinschaft.
Es lohnt sich, auf der Seite ganz nach unten zu gehen, denn dort finden sich die Links zu ausgewählten Beispielen und einer hervorragenden und regelmässig aktualisierten Dokumentation zur Programmiersprache Snap!.
Online-Kurse
Zu Snap! gibt es unterdessen eine Reihe von hervorragenden Onlinekursen über die MOOC-Plattform openSAP:
Build your own Snap! Workshop (Jadga Huegle und Jens Mönig) zeigt auf, wie Snap! in der Arbeit mit Kindern und Jugendlichen verwendet werden kann.
Programmieren mit Snap! (Jadga Huegle und Jens Mönig) bietet eine gute Einführung in Snap! und Grundlagen der Informatik für Kinder und Jugendliche.
Informatik für Einsteiger (Eckart Modrow, Verfasser des gleichnamigen Buches) führt mit Snap! in die Informatik ein und richtet sich an ältere Jugendliche oder Erwachsene.
From Media Computation to Data Science (Jadga Huegle und Jens Mönig) erklärt die Verarbeitung und Repräsentation von Daten mithilfe von Snap! Dieser Kurs hat den Workshop „Zahlen, Daten und Medien“ wesentlich angeregt.
Die Welt der KI entdecken (Stefan Seegerer und Tilman Michaeli) führt in die Thematik der künstlichen Intelligenz ein und nutzt Snap! für praktische Beispiele.
Snap!Con
Seit dem Ausbruch der COVID-19 Pandemie findet die Snap!Con und daran angebundene Veranstaltungen (auch) online statt. Die nächste Snap!Con dauert fünf Tage und wird vom 29. Juli bis 1. August 2021 durchgeführt. Meist bietet die Snap!Con eine Mischung von Beiträgen, die von Anfängerveranstaltungen bis zum Austausch von Experten reichen. Allen ist gemeinsam, dass die Teilnehmenden sich darüber austauschen, wie die Programmierung (und der Unterricht) mit Snap! verbessert werden kann.
YouTube-Videos
Auf YouTube finden sich hervorragende Videos zu Snap! Diese sind teilweise im Rahmen von Snap!Con-Beiträgen entstanden. Da der Begriff „Snap“ auch im anderen Zusammenhang häufig verwendet wird, lohnt es sich, nach „Snap!Con“ oder „Jens Mönig“ zu suchen.
Wer kein Problem mit Englisch hat, dem seien die folgenden zwei längeren Vorträge von Jens Mönig empfohlen:
In The music comes out of the piano räumt Jens Mönig mit der Vorstellung auf, Informatik könne nur durch maximale Abstraktion und möglichst weit weg von Computern unterrichtet werden.
In No code, no limit zeigt Jens Mönig, wie mit Snap! Algorithmen einfach umgesetzt werden können.
Twitter
Eine ganze Reihe von Personen, die sich stark für und rund um Snap! organisieren, berichten regelmässig über ihre Arbeit auf Twitter. Folgende Twitteraccounts sollte man bei Interesse deshalb regelmässig konsultieren:
Jens Mönig: https://twitter.com/moenig ist hauptverantwortlich für die Programmierung von Snap! und freut sich über alle Beiträge zum Thema.
Jagda Hüegle: https://twitter.com/jadga_h überlegt sich unermüdlich, wie Snap! in und ausserhalb des Unterrichts eingesetzt werden kann.
Bernat Romagosa: https://twitter.com/bromagosa engagiert sich allgemein für blockbasierte Sprachen und findet immer wieder verblüffende Anwendungen dafür.
Joachim Wedekind: https://twitter.com/jowedebeschäftigt sich vor allem mit Computerkunst und optischen Illusionen.
Immer wieder steht man als Lehrperson vor der Aufgabe, Anleitungen zu verschiedenen Softwareanwendungen zu schreiben. Dabei steht man dann vor der Entscheidung, ob man ein entsprechendes Tutorial verfasst oder ein Video aufnimmt.
Tutorials lassen sich zwar mit einem vergleichsweisen geringen Aufwand schreiben, für Lernende kann es aber eine Herausforderung sein, sich darin zurechtzufinden. Videos sind meist einfacher nachzuvollziehen, dafür sind sie in der Herstellung aufwändiger und müssen bei Aktualisierungen der Software unter Umständen neu gedreht werden.
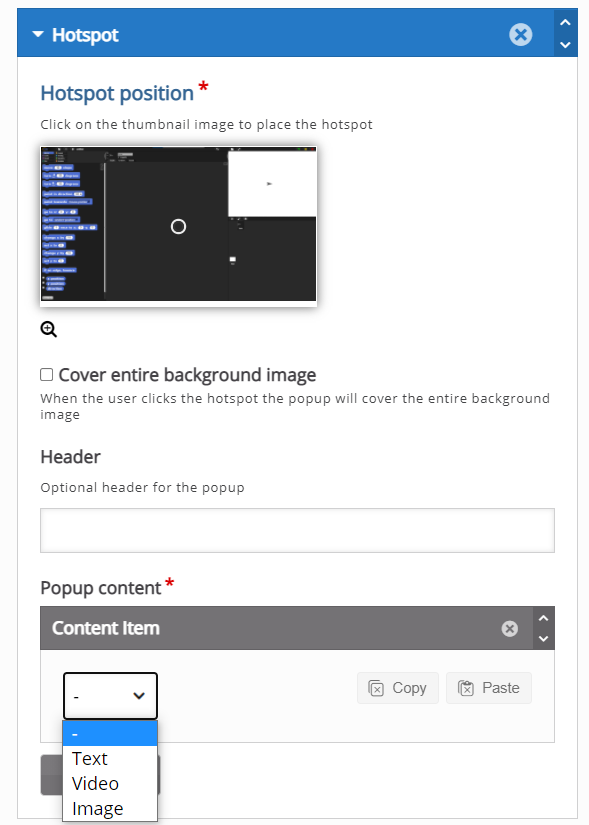
Einen Ausweg aus diesem Dilemma bietet H5P Image Hotspots, weil damit Anleitungen modular geschrieben werden können. Ausserdem lassen so geschriebene Anleitungen den Lernenden die Wahl, mit welchem Aspekt sie sich zuerst beschäftigen wollen.
Beispiel: Snap!-Editor
Am Beispiel der blockbasierten Programmierumgebung Snap! soll gezeigt werden, was mit H5P Hotspots möglich ist. Die Darstellung der einzelnen Informationspunkte ist in Moodle besser gelöst als in WordPress, wo diese vergleichsweise (zu) gross angezeigt werden.
Mit H5P Image Hotspots lassen sich also problemlos Texte, Bilder und Video kombinieren. Den Lernenden wird die Orientierung erleichtert, weil sie die Anleitung zu den Elementen dort finden, wo sie in der Software aufgerufen werden können.
Erstellen eines Lernobjekts mit H5P Hotspots
Nachdem man die Aktivität „Image Hotspots“ ausgewählt hat, lädt man zuerst ein passendes Bild, z.B. der Benutzeroberfläche von Snap! hoch.
Über die entsprechende Schaltfläche kann man ein Hintergrundbild für das Lernobjekt hochladen.
Ist dies geschehen, kann man einen schon bestehenden Hotspot definieren oder über die Schaltfläche „Add Hotspot“ einen neuen generieren.
Zu einem bestehenden Hintergrundbild können beliebig viele Hotspots hinzugefügt werden.
Dazu legt man zuerst die Zielposition des neuen Hotspots fest, dabei hilft unter Umständen ein Klick auf die Lupe unter dem Bild, welches dieses vergrössert und damit eine genauere Positionierung erlaubt.
Über die Schaltfläche „Cover entire background image“ kann man festlegen, wie viel Platz sich öffnende Fenster einnehmen. Der „Header“ dient als Überschrift dieser Fenster.
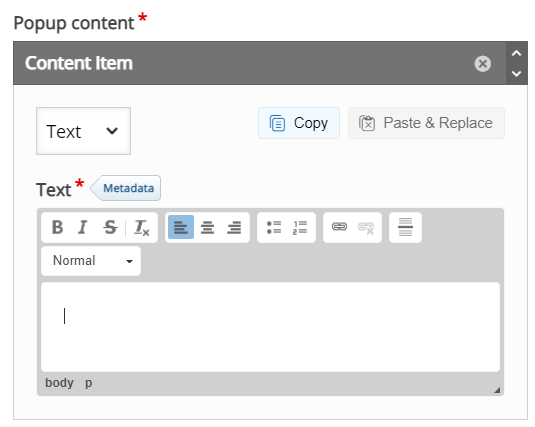
Anschliessend hat man die Wahl zwischen drei verschiedenen Inhalten: Text, Video und Bild. Diese lassen sich über die Schaltfläche „Add item“ auch kombinieren, somit wird eine beliebige Abfolge von solchen Elementen möglich.
Wird der Typ Text gewählt, öffnet sich ein einfacher Editor, mit dem ein zu erstellender oder bereits vorhandener Text bearbeitet werden kann.
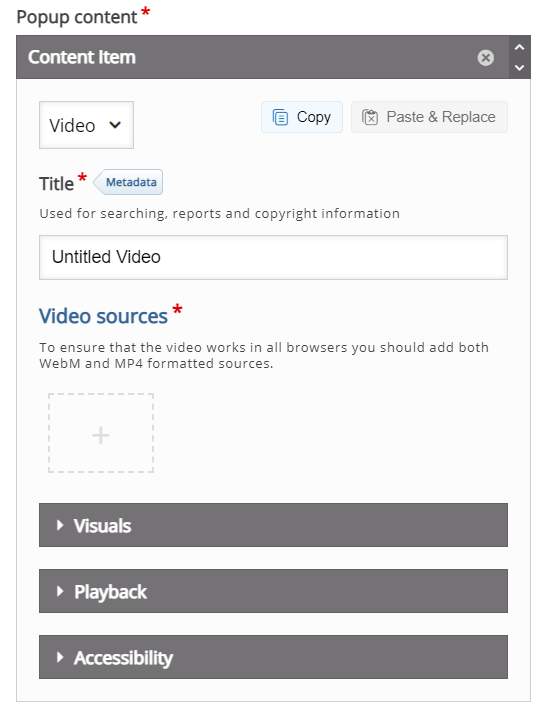
Möchte man ein Element wieder löschen, klickt man auf das „x“ oben rechts im Dialog und bestätigt die entsprechende Rückfrage. Diese erscheint auch dann, wenn man den Typ, beispielsweise zu Video wechselt.
Für das Videoelement können lokal gespeicherte Videos oder Aufnahmen von YouTube verwendet werden.
Um ein Video hinzuzufügen, klickt man auf die gestrichelt umrahmte Schaltfläche mit dem Plus in der Mitte. Anschliessend kann man entweder ein lokales Video hochladen oder den Link zu einem YouTube-Video einfügen.
Die Feineinstellung erfolgt dann über die weiteren Optionen:
Visuals
Hier kann ein Vorschaubild eingefügt werden und bestimmt werden, wie der Videoplayer in der Aktivität angezeigt wird.
Playback
Hier kann man einstellen ob ein Video direkt und evt. wiederholt abgespielt wird. In der Regel sollte man beide Optionen nicht aktivieren, da es viele Nutzer nicht schätzen, wenn plötzlich irgendwo ein Video abgespielt wird.
Accessibility
Hier können Untertitel im WebVTT-Format hinzugefügt werden. Untertitel von YouTube-Videos stehen automatisch zu Verfügung.
Verwendung im Unterricht
H5P Image Hotspots kann nicht nur verwendet werden, um Lernende in die Oberfläche von Softwareanwendungen einzuführen. Der Aufgabentyp eignet sich allgemein dafür, Bildmaterial mit zusätzlichen Informationen anzureichern und hilft damit, den Blick der Lernenden auf wesentliche Details zu lenken.
Die Auswertung von Daten gehört zu den Kernkompetenzen einer Gesellschaft, welche wissensbasiert handeln will. Deshalb erklärt auch der Lehrplan der Deutschschweiz das Auswerten von Daten aus der Umwelt der Schülerinnen und Schüler als eines der übergeordneten Ziele des Informatikunterrichts. Darauf hat unter anderem auch das Statistische Amt des Kantons Zürich reagiert und eine Webseite zum Thema Daten- & Statistikkompetenz aufgeschaltet, welche sich an Lernende wendet. Nebst theoretischen Überlegungen zur Wissenspyramide stellt das Amt auch einen Datensatz mit CO2-Daten zu Verfügung, der von den Lernenden analysiert werden kann. Diese Daten sollen dann mit der Statistiksoftware R und einem Beispielskript ausgewertet werden.
R für die Sekundarstufe I?
R ist ein sehr mächtiges, frei erhältliches und quelloffenes Statistikwerkzeug, welches durch zahlreiche Erweiterungen sich an die individuellen Bedürfnisse von Statistikerinnen und Statistikern anpassen lässt. Da es ausserdem über eine Skriptsprache gesteuert wird, lassen sich mit R durchgeführte statistische Analysen auch leicht nachvollziehen – vorausgesetzt, man kennt sich mit dem Werkzeug aus.
Diese Steuerung der Software über Textelemente führt aber auch dazu, dass viele Menschen sich mit R schwertun, da die Lernkurve ziemlich steil sein kann. Auf der Sekundarstufe I kommt hinzu, dass man nicht zwingend davon ausgehen kann, dass die Lernenden über genügende Fertigkeiten in Bezug auf das Tastaturschreiben verfügen, was die Hürde zusätzlich erhöhen kann. Nun ist es durchaus machbar, mit Schülerinnen und Schülern dieses Alters R zu verwenden, in der Regel bedarf dies aber viel Unterstützung durch die Lehrperson oder dann beschränkt sich die Auseinandersetzung auf eine relativ triviale Abarbeitung eines vorgefertigten Skripts mit geringer Wahrscheinlichkeit auf einen späteren Transfer. Ausserdem steht der Unterricht auf der Sekundarstufe I auch unter einem hohen Druck, die Lernenden dazu zu befähigen, die vielfältigen Kompetenzen des Lehrplans zu meistern und der Umgang von Daten ist nur einer von sieben Teilen im Bereich Medien und Informatik.
Rettung durch die Tabellenkalkulation?
Wäre es da nicht sinnvoll, auf eine bei den Schülerinnen und Schülern bekanntere und einfacher zu bedienende Software wie eine Tabellenkalkulation umzusteigen? Um eine Antwort auf diese Frage zu erhalten, müssen verschiedene Aspekte berücksichtigt werden:
Der Datensatz selbst: Bei einfach aufgebauten oder kleinen Datensätzen mag eine Tabellenkalkulation die erste Wahl sein. Der CO2-Datensatz enthält aber über 2000 Datensätze, was einer Bearbeitung in einer Tabellenkalkulation nicht gerade entgegenkommt. Bei solch grossen Datensätzen ist es schwierig, den Überblick zu behalten.
Das Ziel der Auswertung: Wenn es darum geht, schnell eine Summe zu berechnen oder eine Linien- oder Balkengrafik zu zeichnen, dass ist die Tabellenkalkulation meist die erste Wahl. Wenn aber umfassendere Untersuchungen durchgeführt werden sollen, kann es schwierig sein, die einzelnen Schritte im Prozess nachzuvollziehen und auf eine andere Datenlage anzuwenden. Und genau dies soll ja eines der Ziele der Arbeit mit dem CO2-Datensatz sein. Es geht nicht nur darum, Erkenntnisse über diesen einzelnen Datensatz zu gewinnen, sondern diese Kenntnisse später auch auf andere Daten anzuwenden, bei denen vielleicht eine ganz andere Fragestellung im Fokus steht.
Die Methodik: In der Mathematik, Informatik und den Naturwissenschaften ist es üblich, mit Werkzeugen zu arbeiten, bei denen Arbeitsschritte nachvollziehbar sind. Eine Reihe von abzuarbeitenden Befehlen erfüllt diese Aufgabe in der Regel besser, als wenn man auf eine grafische Oberfläche setzt, wie dies bei der typischen Tabellenkalkulation der Fall ist. Die schlechte Nachvollziehbarkeit von Analysen mit Tabellenkalkulationen führt dann auch immer wieder zu Problemen. Dass dabei ein Produkt besonders häufig genannt wird, hat weniger mit dessen Qualität als vielmehr dessen grosser Verbreitung zu tun.
Diese Überlegungen zeigen, dass anscheinend nur die Wahl zwischen der unzugänglichen Arbeit mit einer Skriptsprache wie R oder der in den Naturwissenschaften eher weniger gern gesehenen, weil schlecht reproduzierbaren Arbeit mit einer Tabellenkalkulation bleibt.
Zu erreichende Ziele
In ein solches Dilemma verstrickt, lohnt es, sich noch einmal die Zielsetzungen vor Augen zu führen. Was sollen die Lernenden aus der Auseinandersetzung mit dem Lernobjekt (hier ein für Schulverhältnisse vergleichsweise grosser Datensatz) mitnehmen?
Die Lernenden sollen eine grundsätzliche Fertigkeit im Umgang mit grösseren Datenmengen erwerben. Dazu gehören unter anderem:
Sich einen Überblick und die Inhalte des Datensatzes zu verschaffen;
einfache statistische Berechnungen auf den Datensatz anzuwenden;
den Datensatz möglicherweise visuell auszuwerten (wird in diesem Beitrag nicht behandelt);
Die Lernenden sollen dabei Methoden kennenlernen, welche typisch für das entsprechende professionelle Umfeld sind. Dazu gehören:
Die Arbeitsweise mit einer professionellen Statistiksoftware zumindest in Ansätzen kennen lernen;
bei der Arbeit mit Daten auf die Reproduzierbarkeit der Berechnungen zu achten;
Einblick in die Funktionsweise statistischer Methoden erlangen.
Grundsätzlich würde R diese Bedingungen erfüllen, den Anwender wird der Einstieg durch die neu zu erlernenden Konzepte mit der gleichzeitig abverlangten Genauigkeit beim Eingeben der Befehle (Tippfehler) aber erschwert. Eine didaktische Reduzierung auf den eigentlichen Kern, die Nutzung von flexiblen, reproduzierbaren Befehlen zum Umgang mit Daten ist also angesagt.
In den folgenden Ausführungen soll nun gezeigt werden, dass eine Sprache wie Snap! aufgrund der blockbasierten Schnittstelle dazu ideale Voraussetzungen bietet und damit den Lernenden einen späteren Umstieg auf ein Statistikprogramm wie R wesentlich erleichtern kann.
Umsetzung mit Snap!
Da Snap! es ermöglicht, eigene Blöcke (Funktionen, Befehle, …) zu schreiben, kann die benötigte Funktionalität den Lernenden entweder zu Verfügung gestellt werden, oder, falls dies erwünscht ist, können diese die Erweiterungen selbst schreiben oder zumindest deren Funktionsweise nachvollziehen.
Während Snap! schon von Grund auf viele interessante Blöcke enthält und diese durch bereits vorhandene Bibliotheken (z.B. Frequency Distribution Analysis, Variadic reporters) ergänzt werden können, ist zumindest bei einer ersten Auseinandersetzung mit grösseren Daten sinnvoll, den Lernenden entsprechend zugeschnittene Blöcke zu Verfügung zu stellen.
Deshalb ist es sinnvoll, einmal einen Blick in den entsprechenden Auftrag zum CO2-Datensatz zu werfen (siehe R Skript). Die Lernenden sollen …
die Grösse des Datensatzes bestimmen (Anzahl Spalten und Zeilen);
die Überschriften der einzelnen Spalten herauslesen;
die Zeitabstände zwischen den Messzeitpunkten berechnen;
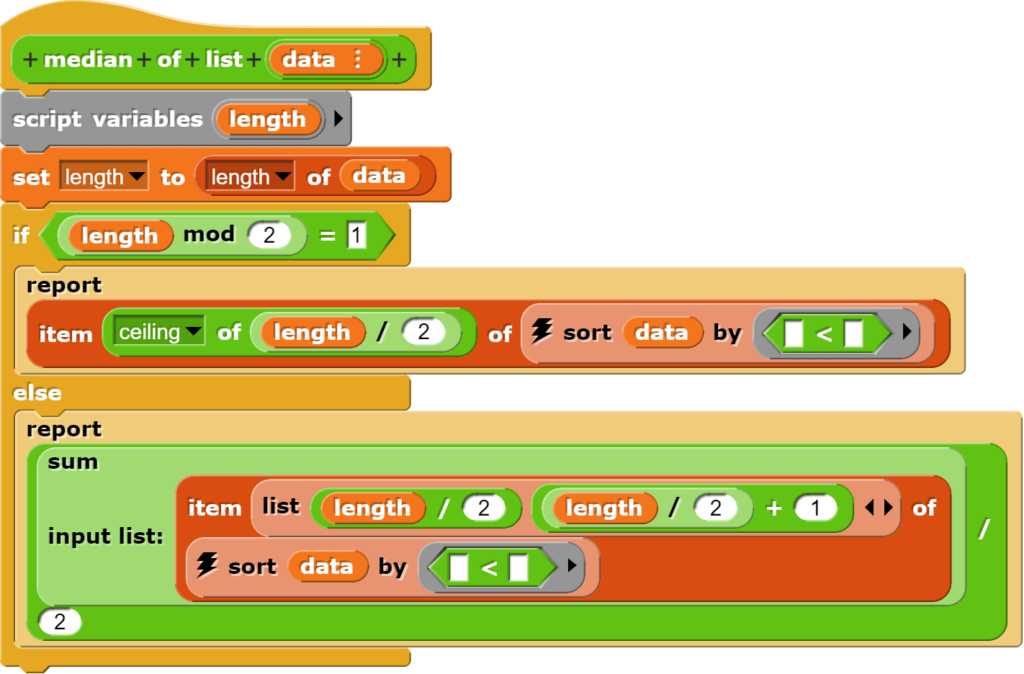
den Mittelwert (mean), Zentralwert (median) und häufigst vorkommenden Wert (modus) bestimmen;
Minimum und Maximum, sowie die Spannweite feststellen;
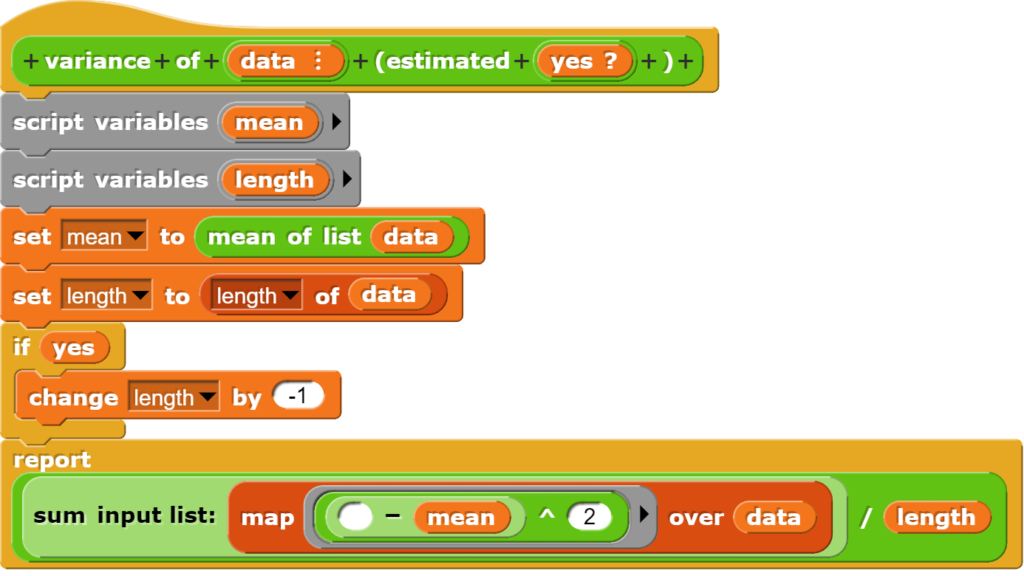
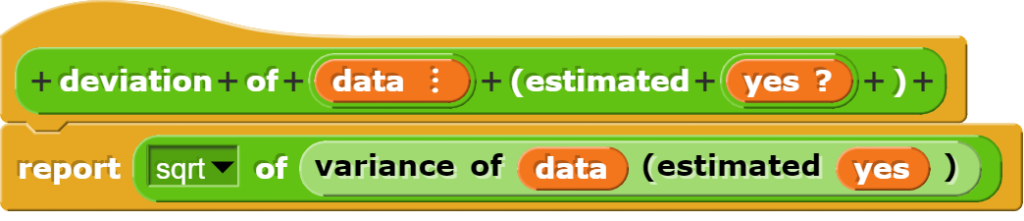
die Standardabweichung (standard deviation) und Streuung (variance) berechnen;
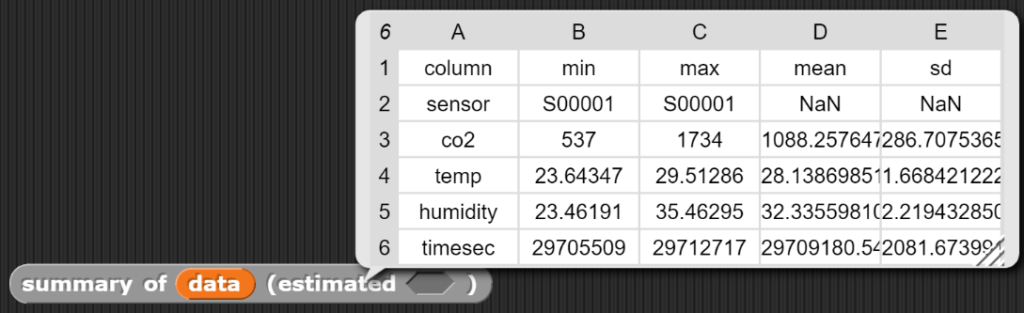
eine Übersichtstabelle (summary) zu den Daten generieren.
Nachdem die Aufgabenstellungen klar sind, können die entsprechenden Befehle zu Verfügung gestellt werden.
Didaktische Überlegungen
Bei der Umsetzung der entsprechenden Blöcke stellten sich erneut verschiedene Fragen:
Soll sich die Bezeichnung der Blöcke an diejenige der Skriptsprache R anlehnen?
Welchen Abstraktionsgrad sollen die einzelnen Blöcke aufweisen?
Wie fehlertolerant sollen die Eingabemöglichkeiten zu den Blöcken gestaltet werden?
Im Zweifelsfalle: Soll der Fokus beim Schreiben von Blöcken auf die Effizienz oder Nachvollziehbarkeit gelegt werden?
Die Beantwortung dieser Fragen führt unweigerlich zu entsprechenden Designentscheidungen. Grundsätzlich können diese aber später korrigiert werden, zumindest dann, wenn nur die Namen einzelner Blöcke und deren Programmierung angepasst werden, nicht aber deren Schnittstelle gegen aussen geändert wird. Bereits hier zeigt es sich, dass auch vergleichsweise triviale Aufgabenstellungen in Snap! sehr schnell zu Fragen führen, die über das eigentliche Programmieren hinausgehen und eigentliche Aufgaben der Informatik sind.
Für die konkrete Umsetzung wurden die Fragestellungen wie folgt beantwortet:
Eine Übernahme der genauen Bezeichnungen von R wurde als nicht erstrebenswert angesehen, da es darum geht, die Prinzipien zu verstehen. Ansonsten hätte man auch einfach das vorhandene Skript abarbeiten können. Die Lernenden sollen die Grundprinzipien erlernen, nicht eine ganz bestimmte Umsetzung in einer Sprache wie R.
Die Blöcke dürfen einen unterschiedlichen Abstraktionsgrad aufweisen, d.h., die Lernenden sollen bei Bedarf auch Blöcke mit einem tieferen Abstraktionsgrad nutzen können. Zudem ist es in Snap! bei den meisten (bei allen selbstgeschriebenen) Blöcken möglich, die entsprechende Programmierung einzusehen.
Die Fehlertoleranz der einzelnen Blöcke ist momentan auf unterschiedlichem Niveau (aus Zeitgründen) und soll deshalb erst einmal dokumentiert werden. Diese kann aber später bei Bedarf nachgerüstet werden. Didaktisch kann es sinnvoll sein, mit den Lernenden darüber zu sprechen, weshalb einige Blöcke weniger fehlertolerant sind als andere und was notwendig ist, um eine solche Fehlertoleranz zu erzielen.
Beim Schreiben der Blöcke wurde der Fokus auf die Nachvollziehbarkeit gelegt, wobei häufig Prinzipien genutzt werden, die typischerweise auch bei R zu finden sind.
Blöcke zum Filtern von Daten
Die meisten Blöcke wurden so umgesetzt, dass sie mit dem ganzen Datensatz (inklusive Spaltenüberschriften) funktionieren. Für die bessere Nachvollziehbarkeit werden die Blöcke inklusive der entsprechenden Programmierung vorgestellt
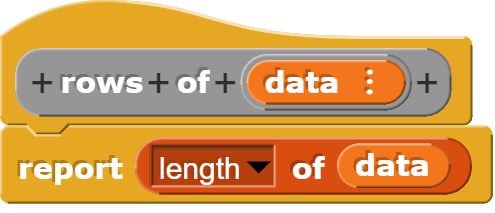
Namen der Spaltenüberschriften bestimmen
Mit diesem Block wird die Zeile 1 der CSV-Tabelle ausgelesen und als Liste zurückgegeben. Die Programmierung zeigt, dass dafür eigentlich kein eigener Block notwendig ist, denn er verpackt nur bereits vorhandene Funktionalität und macht sie damit etwas benutzerfreundlicher.
Dieser Block liefert die Spaltenüberschriften zurück.
Anzahl der Zeilen und Spalten bestimmen
Zeilen und Spalten unterscheiden sich in einer Tabelle in Snap! konzeptionell, weshalb der Zugriff jeweils anders erfolgt. Um die Zahl der Spalten zu erhalten, geht man gleich vor. wie im oberen Beispiel geschildert. Nur bestimmt man zusätzlich noch, wie lang die zurückgegebene Liste ist.
Der Befehl gibt die Zahl der Spalten zurück.
Der Befehl für die Zahl der Zeilen einer Tabelle, verpackt wieder nur einen schon bestehenden Block.
Der Block gibt die Zahl der Zeilen in einer Tabelle zurück.
Wenn man ganz auf selbstgeschriebene Blöcke verzichten möchte, kann man auch einen bereits vorhandenen Block in Snap verwenden:
Anzahl der Zeilen und Spalten in einer Tabelle
Dieser Block liefert die Dimensionen einer Tabelle als Liste der Form (Zeilenzahl, Spaltenzahl) zurück.
Nummer einer Spalte mit einer bestimmten Überschrift
Dieser Block dient nur dem Komfort. Anstatt eine Spalte über ihre Nummer zu adressieren, geht dies auch mit der Spaltenüberschrift.
Dieser Block gibt die Nummer der Spalte mit der entsprechenden Überschrift zurück.
Hier wurde aufgrund der einfachen Programmierung darauf verzichtet, auf den schon bestehenden Block „names of colums of“ zurückzugreifen.
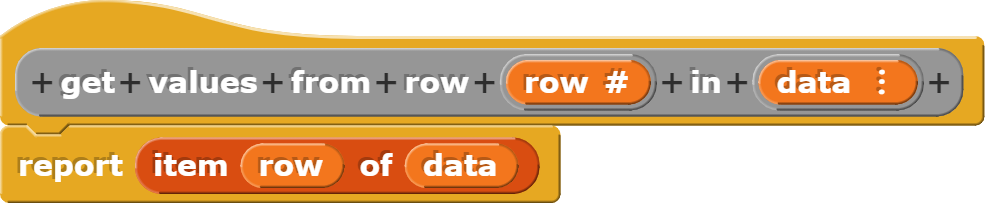
Eine Datenzeile auslesen
Bei diesem Block handelt es sich um eine Verallgemeinerung des Blockes zum Auslesen der Spaltenüberschriften. Damit können die Werte einer beliebigen Zeile ausgelesen werden.
Dieser Block gibt alle Werte in einer bestimmten Zeile der Tabelle zurück.
Eine Spalte auslesen
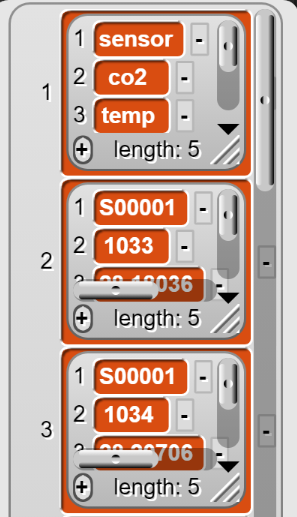
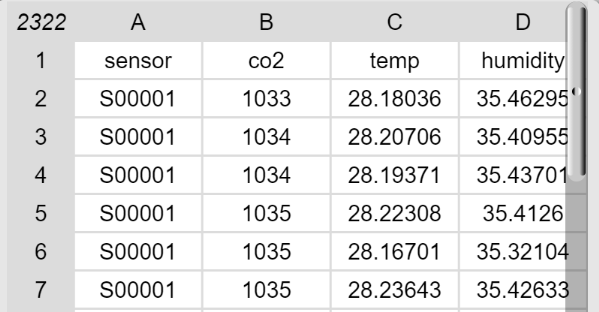
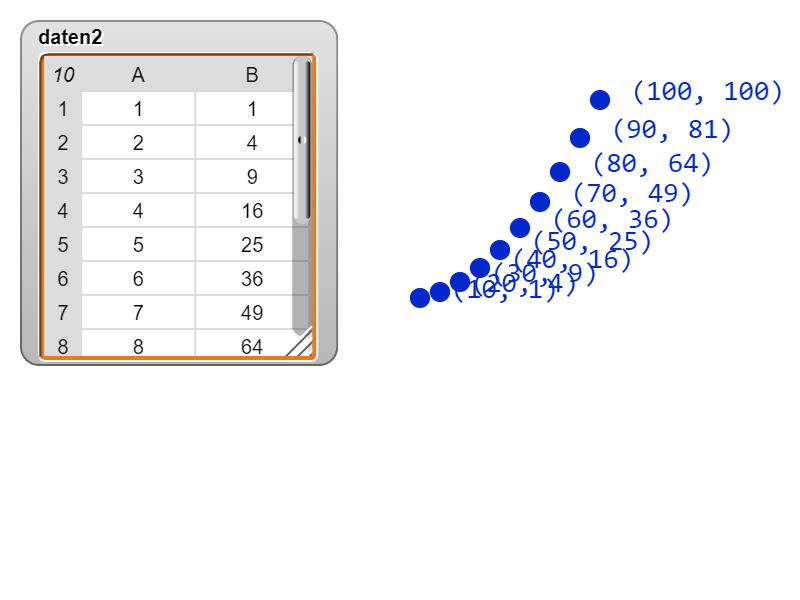
Da Snap! Tabellen als Listen von Listen darstellt, ist das Auslesen der Werte in einer Spalte etwas komplizierter als bei einer Zeile. Die ersten drei Zeilen des Datensatzes werden bei Snap! so repräsentiert:
Tabellen werden in Snap! als Listen von Listen dargestellt.
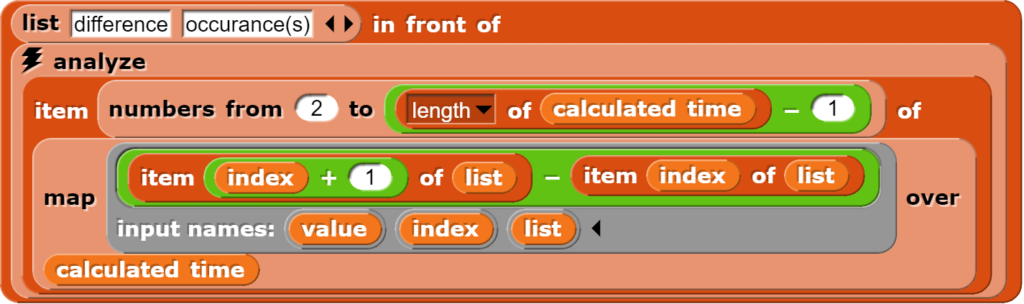
Aus diesem Grund muss aus jeder Liste (eine Zeile der Daten) jeweils der entsprechende Wert ausgelesen und anschliessend in eine neue Liste geschrieben werden. Dies geschieht mithilfe des map-Blockes.
Dieser Block liefert alle Daten in einer Spalte der Tabelle zurück.
Der map-Block führt einen Befehl über alle Elemente einer Liste aus und ist ein sehr wichtiges Werkzeug, welches auch in R zu Verfügung steht. Dort bei Nutzenden, welche R nicht gut kennen, aber gerne durch eine wesentlich ineffizientere for-Schleife ersetzt wird. Fall die Zeit vorhanden ist, lohnt es sich, mit den Lernenden den map-Block eingehender zu behandeln, da damit in vielen Fällen das Konzept der for-Schleife zu Seite gelegt werden kann.
Grundsätzlich gilt in Snap!: Wenn möglich sollte man eine For-Schlaufe durch einen forEach-Block ersetzen und diesen gegebenenfalls wiederum durch einen map-Block. Dabei verliert man unter Umständen etwas Flexibilität, die Programmierung wird aber eleganter und vor allem werden die Befehle schnell ausgeführt.
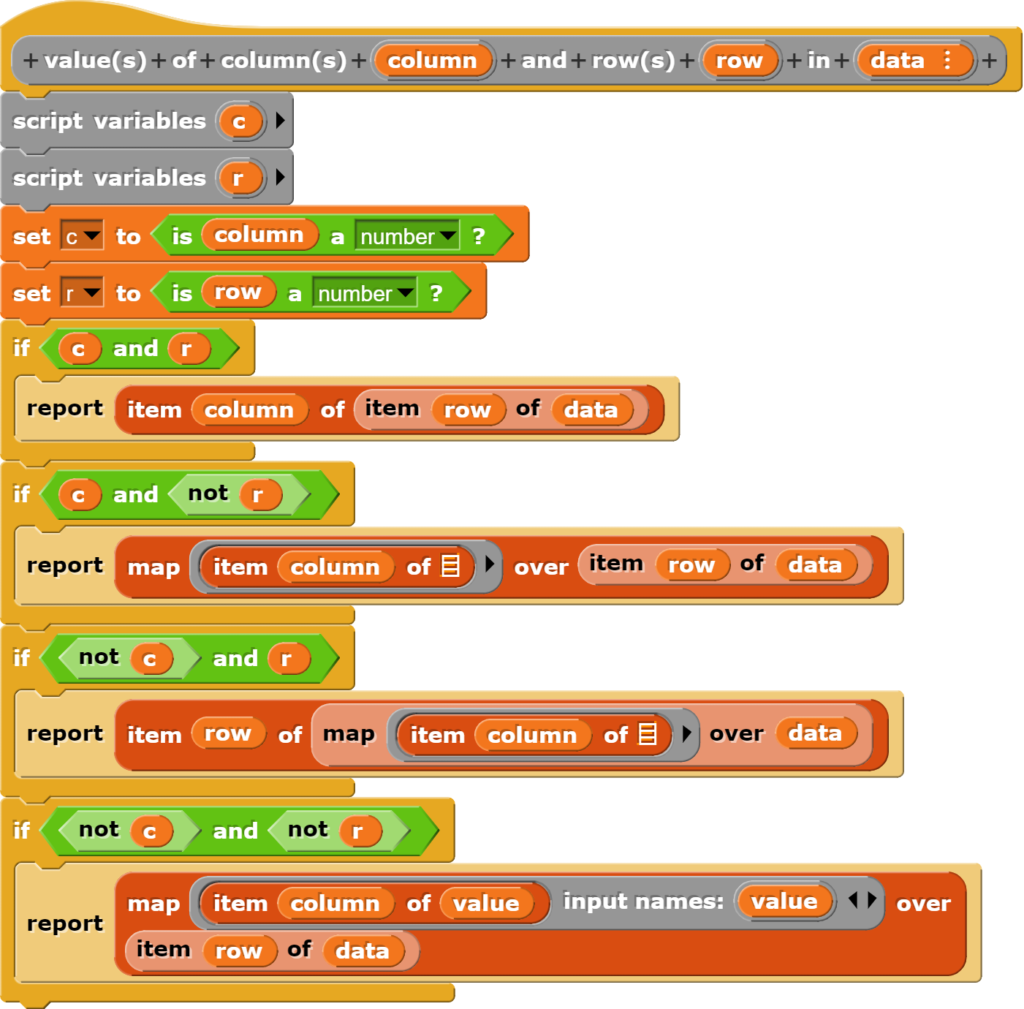
Einen Datenbereich auslesen
Manchmal möchte man statt nur einer Zeile oder einer Spalte einen Datenbereich auslesen. Bei sehr grossen Datensätzen wendet man beispielsweise beim Schreiben eines Skriptes die Befehle nur auf einen Teil des Datensatzes an, weil sonst die Berechnungen zu lange dauern. Ist man sich sicher, dass das eigene Programm funktioniert, lässt man es über den ganzen Datensatz laufen.
Einen Ausschnitt aus den Daten zu erhalten, funktioniert auch mit einer Abfolge von Befehlen, einfacher geht es aber mit folgendem Block:
Dieser Block liefert einen Teilbereich einer Tabelle zurück.
Nebst dem map-Befehl enthält dieser Block noch die Besonderheit, dass er bei der Eingabe für die Zeile und Spalte sowohl eine Zahl als auch eine Liste entgegennimmt, was normalerweise nicht ohne Weiteres möglich ist. Dazu prüft der Block, ob es sich bei der Eingabe um eine Zahl handelt und verzweigt dann dementsprechend in einen anderen Zweig der Programmierung. Damit versteckt der Block eine technische Schwierigkeit bei der Programmierung mit Snap! vor den Lernenden. Umgesetzt wurde dieser Ansatz hier, weil für Spezialfälle nicht noch eigene Blöcke geschrieben werden sollten.
Tabelle drehen
Manchmal ist es sinnvoll, eine Tabelle um 90° zu drehen, weil dadurch die Auswertung der Daten erleichtert wird.
Dieser Block dreht eine Tabelle um 90°.
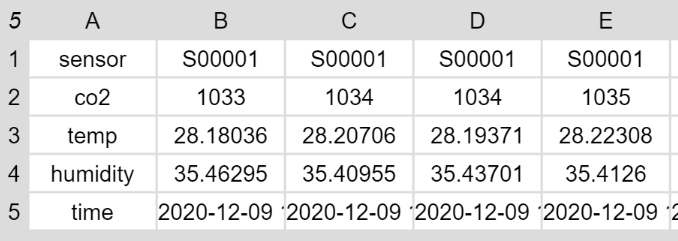
Ein Beispiel soll zeigen, was damit gemeint ist. In Snap! wird die CO2-Tabelle so dargestellt:
Der Anfang des Datensatzes in der Tabellenansicht von Snap!.
Wenn diese um 90° gedreht wird, präsentiert sich die Tabelle so:
Beim Rotieren einer Tabelle werden Zeilen und Spalten vertauscht.
Die Zeilen sind zu Spalten geworden und umgekehrt. Die mit verschachtelten map-Blöcken umgesetzte Funktionalität kann man seit einiger Zeit auch mit einem vorgegebenen Block noch einfacher umgesetzt werden:
Unterdessen kennt Snap! einen eigenen Block zum Drehen von Tabellen.
Zusammenführen von Datensätzen
Der erwähnten Block „columns of“ kann auch dazu verwendet werden, zwei Tabellen mit wenigen Zeilen Code zusammenzuführen.
Dieser Block führt zwei Tabellen zu einer zusammen.
Dabei werden die Daten wieder zuerst gedreht, aneinandergehängt und schliesslich wieder zurückgedreht. Das funktioniert wesentlich einfacher als mit der Verwendung einer expliziten Schlaufe.
Löschen von Spalten in einer Tabelle
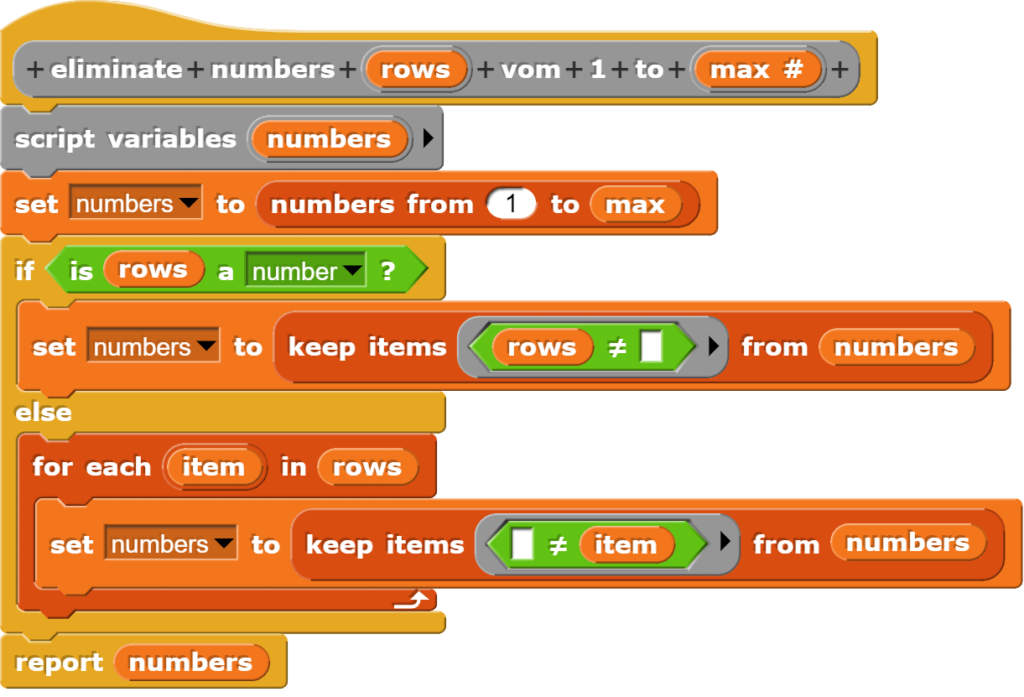
Um eine Spalte in einer Tabelle zu löschen, wird diese unter Verwendung aller Spalten, die nicht gelöscht werden sollen, neu geschrieben. Damit dies einigermassen komfortable funktioniert, wird zuerst eine Hilfsfunktion benötigt, welche eine Liste der Spalten generiert, die behalten werden sollen.
Dieser Block streicht eine Zahl aus einer Zahlenliste.
Dank der Fallunterscheidung funktioniert dies mit einzelnen Zahlen und Listen von Zahlen.
Dieser Block löscht eine Spalte aus einer Tabelle.
Der Block schreibt also die Tabelle neu und verwendet dabei alle Spalter, ausser derjenigen, die eben gelöscht werden soll.
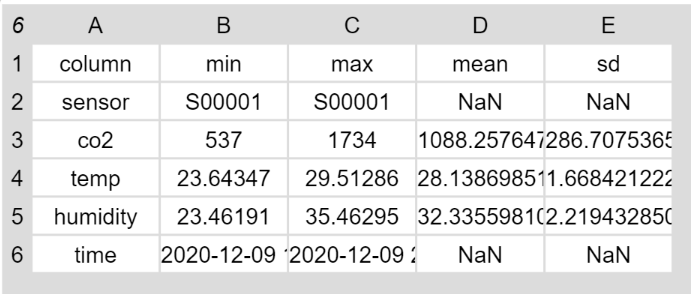
Zusammenfassung der Tabellendaten
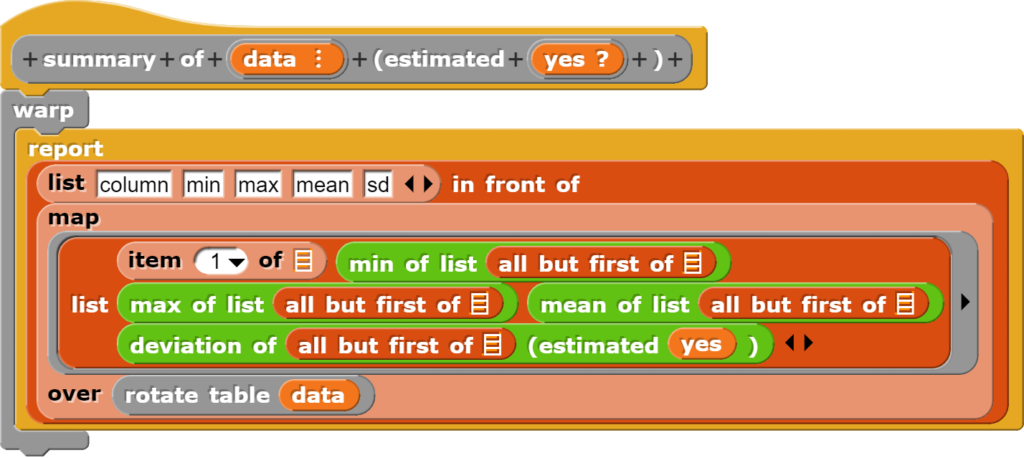
Der Block zur Zusammenfassung der Tabellendaten weist einen wesentlich höheren Abstraktionsgrad auf und greift dabei auf verschiedene bereits vorhandene und zusätzlich geschriebene Blöcke zurück.
Dieser Block liefert eine Tabelle mit den wichtigsten Kenndaten eines Datensatzes zurück.
Grundsätzlich erzeugt der Block eine neue Tabelle mit den Überschriften „column“, „min“, „max“, „mean“ und „sd“. Die eigentliche Tabelle wird erzeugt, indem für jede Spalte die entsprechenden Werte berechnet werden, wobei die Tabelle zur einfacheren Berechnung noch rotiert wird.
Der Block „summary“ liefert eine Zusammenfassung der wichtigsten Kerngrössen.
Blöcke zur Berechnung statistischer Kennwerte
Im nächsten Abschnitt werden Blöcke vorgestellt, die zur Berechnung statistischer Kennwerte verwendet werden können. Damit diese funktionierten, dürfen die zugrundeliegenden Listen in der Regel nur Zahlen enthalten.
Minimum, Maximum und Spannweite
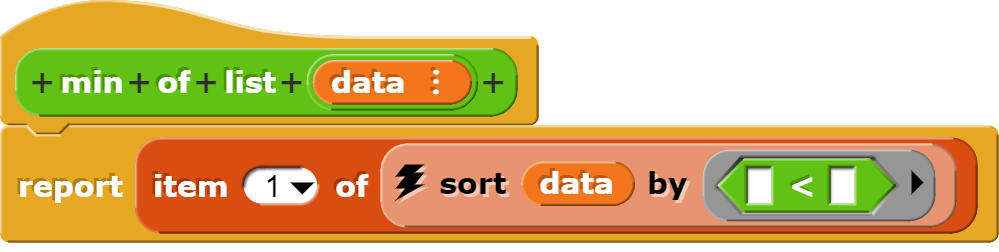
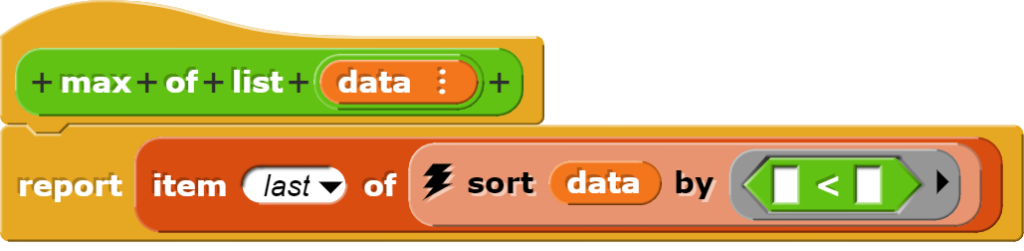
Die Blöcke zur Berechnung des Minimums und Maximums sortieren die Daten zuerst und holen sich dann den ersten, respektive letzten Wert aus der sortierten Liste.
Dieser Block liefert den minimalen Wert in einer Liste von Zahlen.Dieser Block liefert den Maximalwert aus einer Liste von Zahlen zurück.
Natürlich hätte man den max-Block auch so programmieren können, dass man mit dem „grösser als“-Zeichen operiert.
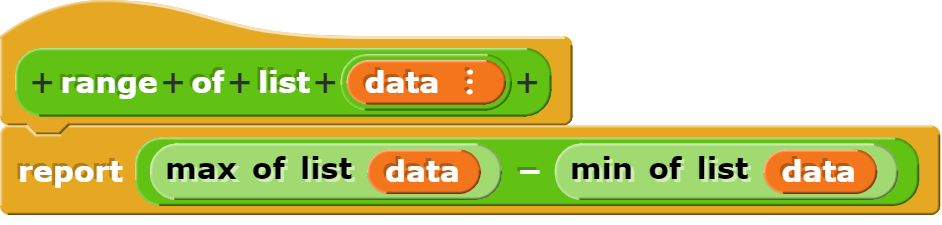
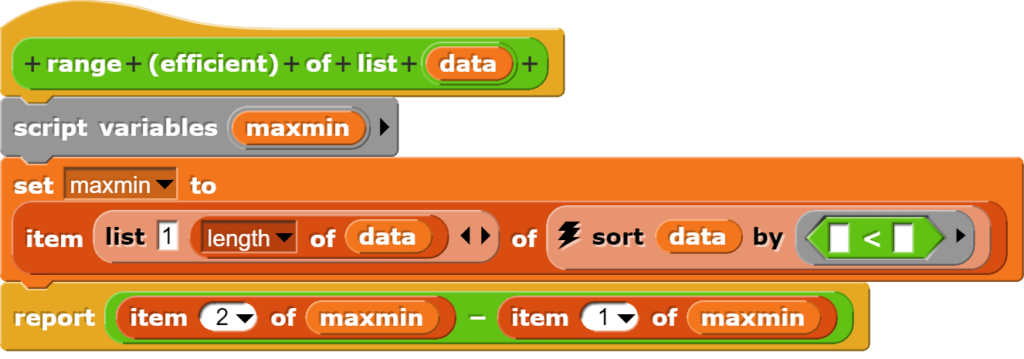
Der Block zur Berechnung der Spannweite ruft einfach „max“ und „min“ auf und berechnet dann die Differenz.
Bei der Programmierung dieses Blocks wurde bewusst auf eine Optimierung (die Liste wird zweimal sortiert) verzichtet, damit klarer wird, dass die Spannweite die Differenz von Maximum und Minimum ist. Wenn mit sehr grossen Datensätzen gearbeitet wird, kann es sinnvoll sein, eine optimierte Version zu verwenden. Diese könnte dann so aussehen:
Durch die Optimierung halbiert sich die Berechnungszeit, dafür ist die Programmierung weniger verständlich.
Da bei ca. 2000 Werten die Berechnungszeit auch bei einem langsameren Computer unter einer Sekunde liegen dürfte, lohnt sich eine solche Anpassung im Schulgebrauch wahrscheinlich nicht.
Anzahl unterschiedlicher Werte
Manchmal ist es praktisch, wenn man weiss, wie viele unterschiedliche Werte sich in einer Spalte einer Tabelle befinden. Programmtechnisch lässt sich dies in Snap! einfach umsetzen.
Dieser Block liefert die Anzahl unterschiedlicher Werte in einer Liste zurück.
Zuerst wird die Liste auf die unterschiedlichen Werte reduziert, anschliessend wird noch die Länge dieser reduzierten Liste abgefragt.
Sinnvoll ist die Anwendung eines solchen Befehls vor allem bei Listen, deren Inhalte nicht aus Zahlen bestehen. Will man den Befehl trotzdem mit Zahlen verwenden, kann man diese beispielsweise runden, um deren Vielfalt zu reduzieren.
Mittelwert, Zentralwert und häufigster Wert
Die Ausführungen zu den drei statistischen Werten (mean, median, modus) sollen sich hier auf die Umsetzung als Snap!-Blöcke beschränken. Am einfachsten ist es, das arithmetische Mittel (mean) zu berechnen.
Dieser Block liefert das arithmetische Mittel aller Werte in einer Liste zurück.
Programmtechnisch wird die Summe aller Werte gebildet, dabei hilft der entsprechende Summenbefehl aus der Bibliothek „Variadic Reporters“, die anschliessend durch die Anzahl der Werte dividiert wird.
Komplizierter ist die Berechnung des Zentralwerts, weil dazu die Liste sortiert und ausserdem eine Fallunterscheidung (gerade oder ungerade Anzahl von Werten) vorgenommen werden muss.
Dieser Block liefert den Zentralwert aus einer Liste von Zahlen zurück.
Zuerst wird mit dem Modulus-Operator geprüft, ob die Anzahl der Werte ungerade ist. Wenn dem so ist, wird die Mitte der Liste bestimmt und der entsprechende Wert zurückgegeben. Handelt es sich um eine gerade Anzahl von Werten, wird aus den beiden Werten in der Mitte das arithmetische Mittel berechnet. Dabei wurde auf einen Einsatz des schon bestehenden Blockes zur Berechnung des arithmetischen Mittels verzichtet, weil die Division mit Zwei in diesem Fall wohl anschaulicher ist.
Am kompliziertesten ist die Berechnung des häufigsten Wertes, auch wenn dies aus der Anzahl der Blockbefehle nicht unmittelbar ersichtlich ist.
Dieser Block liefert den häufigsten in einer Liste von Zahlen vorkommenden Wert zurück.
Die scheinbar nur aus einem Schritt bestehende Programmierung führt folgende Schritte durch: Zuerst werden die Daten mit „analyze“ in Gruppen aufgeteilt und gezählt, aus wie vielen Elementen jeder dieser Gruppe besteht. Anschliessend wird die so berechnete Liste nach der Anzahl der Mitglieder sortiert und ganz zuletzt wird der höchste Wert für eine Anzahl von Elementen zurückgeliefert. Falls es mehrere Höchstwerte mit der gleichen Anzahl von Elementen gibt, wird dies in der Programmierung nicht berücksichtigt. Der Block gibt immer nur einen Wert zurück.
Standardabweichung und Streuung
Die Standardabweichung (standard deviation) und die Streuung (variance) sind beide statistische Kennwerte, die angeben, wie sehr sich die Daten in einem Datensatz voneinander unterscheiden. Bei beiden Werten gibt es jeweils zwei Rechenverfahren, die abhängig davon sind, ob man eine ganze Population oder nur eine Auswahl davon erfasst hat. Auch hier sollen sich die Ausführungen auf die Programmierung beschränken.
Die Varianz berechnet sich als der Durchschnitt der Quadrate der Abweichungen zum Mittelwert der Daten.
Der Block liefert die Streuung zu einer Liste von Zahlen zurück.
Zuerst wird das arithmetische Mittel berechnet, dann wird für jeden Wert die Abweichung vom Mittelwert quadriert und anschliessend die aufsummierten Quadrate durch die Anzahl der Werte (oder Werte -1) dividiert. Bei der Fallunterscheidung wurde nur der Wert für die Anzahl der Listenelemente angepasst, damit im Programmcode weniger von der eigentlichen Berechnung der Werte abgelenkt wird.
Die Standardabweichung kann nur einfach als Quadratwurzel der Streuung berechnet werden.
Dieser Block gibt die Standardabweichung zu einer Liste von Zahlen zurück.
Umgang mit Zeitangaben
Zeitangaben am Computer sind ein kompliziertes Problem ,weil die verschiedenen Umrechnungen, z.B. 60 s = 1 min oder 24 h = 1 d, berücksichtigt werden müssen. Ausserdem gibt es dann noch die Schaltjahre usw. Aus diesem Grund werden Zeitangaben am Computer meist auf Sekunden (oder Millisekunden) umgerechnet, welche seit einem bestimmten Zeitpunkt (beispielsweise dem 1.1.1970) vergangen sind. Bei der Programmierung der entsprechenden Zeitfunktionalität für Snap! wurde ein ähnlicher Ansatz verfolgt. (Es ist natürlich auch möglich, entsprechende Befehle mit einem JavaScript-Block einzufügen, aber das widerspräche dem Versuch, den Lernenden die Grundlagen der Informatik zu vermitteln).
Damit am Schluss die Berechnung der Unterschiede zwischen zwei Zeitangaben einigermassen benutzerfreundlich erfolgen kann, wird zuerst eine Hilfsfunktion definiert, welche den Zeitunterschied zum 1.1. im Jahr 0 berechnet. Aufgrund der heutigen 64bit Betriebssysteme ist eine Beschränkung auf einen kleinen Zeitraum wie 1970 nicht mehr notwendig. Allerdings wurde bei der Programmierung die Umstellung des Julianischen auf den Gregorianischen Kalender Ende des 16. Jahrhunderts nicht berücksichtigt. Daten können aber bis ca. 1600 fast sekundengenaue (Problematik der Schaltsekunde) umgerechnet werden.
Der Block gibt die seit dem Jahr Null vergangene Zeit in Sekunden zurück.
Im Wesentlichen werden alle Bestandteile einer Datums- und Zeitangabe von der Sekunde bis zum Jahr aufaddiert, wobei in Einzelfällen noch Rahmenbedingungen (Tage und Monate beginnen bei der Zählung mit 1) und Spezialfälle (wie Schaltjahre) berücksichtigt werden).
Die Problematik der Schaltjahre wurde dabei wiederum in einen eigenen Block ausgelagert.
Der Blockliefert die Tage pro Monat oder in einem Jahr unter Berücksichtigung eines Schaltjahres zurück.
Dabei gibt der Block die zu berücksichtigen Tage entweder als Liste (Monate) oder als Summe (Jahr) zurück.
Mithilfe dieser Blöcke kann nun der für die Lernenden eigentlich interessante Block umgesetzt werden. Dieser bietet eine etwas angenehmere Schnittstelle an, bei der die Zeitangaben einfach im in den CO2-Daten vorhandenen Zeitformat übernommen werden können.
Dieser Block nimmt Zeitangaben im Format „yyyy-mm-dd hh:mm:ss“ entgegen und rechnet diese in Sekunden seit dem Jahr Null um.
Weil dabei unter Umständen mehr als 2000 Jahre aussummiert werden müssen, kann noch mit einer Zeitkorrektur gearbeitet werden, welche die Berechnungszeit wesentlich reduziert.
Beispiel zur Bearbeitung von Daten
Eine interessante Fragestellung zu den Daten des Statistischen Amtes des Kantons Zürich ist die nach den Zeitabständen zwischen den einzelnen Messungen im Beispieldatensatz. Um mehr darüber zu erfahren, können in Snap! folgende Schritte ausgeführt werden.
Die vorhandenen Zeitangaben werden in Sekunden umgerechnet.
Der Datensatz wird mit diesen Angaben erweitert und die nicht mehr benötigte Spalte „time“ allenfalls entfernt.
Die Zeitunterschiede zwischen den Messungen werden berechnet und nach der Grösse des Zeitunterschiedes oder der Häufigkeit gruppiert.
Umrechnung der Zeitangaben
Für die Umrechnung der Zeitangaben kann man auf den bereits beschriebenen Block zurückgreifen. Da alle Zeitangaben in den Beispieldaten aus dem Jahr 2020 stammen, wird die Berechnung aus Effizienzgründen um diesen Wert korrigiert. Die so entstandene Liste wird in einer temporären Variablen abgespeichert (und kann später wieder gelöscht werden).
Alle Zeitangaben werden in Sekunden umgerechnet.
Anpassen des Datensatzes
Die so berechneten Werte fügen wir nun zur schon vorhandenen Tabelle hinzu.
Mit dem entsprechenden Befehl können Tabellen leicht zusammengeführt werden.
Zum Löschen der nun nicht mehr benötigten Spalte „time“, kann auf bereits vorhandene Befehle zurückgegriffen werden. Um Fehler zu vermeiden, soll dabei die Spaltenzahl aufgrund der Spaltenüberschrift ermittelt werden. Dies verhindert auch Probleme, wenn sich eine Spalte nicht am Ende der Tabelle befindet und Lernende ungeduldig mehrfach einen Block anklicken.
Die nicht mehr benötigte Spalte „time“ kann gelöscht werden.
Den Erfolg der durchgeführten Operation sollte man von Zeit zu Zeit überprüfen, was mit dem summary-Block geschehen kann.
Die Zusammenfassung zeigt, dass die geplanten Operationen erfolgreich durchgeführt wurden.
Zeitunterschiede berechnen
Im nächsten Schritt werden nun die Zeitunterschiede zwischen den Messungen berechnet. Da dazu die eigentliche Tabelle nicht benötigt wird, kann auf die temporäre Liste „calculated time“ zurückgegriffen werden.
Die Zeitdifferenzen können mit einem verschachtelten Block berechnet und ausgewertet werden.
Der Block berechnet zuerst alle Differenzen zwischen jeweils nachfolgenden Zeilen, wobei der erste und letzte Wert verworfen werden, da diese Berechnungen kein sinnvolles Ergebnis liefern, dann wird ausgezählt wie viele Male jede Differenz vorkommt und die so entstandene Tabelle noch mit entsprechenden Überschriften versehen.
Fazit
Anhand der CO2-Daten des Statistischen Amtes des Kantons Zürich wurde aufgezeigt, wie Snap! als Alternative zu einer professionellen Statistiksoftware wie R für die deskriptive Datenanalyse verwendet werden kann. Fehlende Funktionalitäten können dabei auf beliebigem Abstraktionsniveau ergänzt werden. Aufgrund der Flexibilität von Snap! kann damit eine typische Vorgehensweise von R gut nachgebildet werden, ohne dass man sich dabei die Schwierigkeiten einer textbasierten Programmiersprache einhandelt.
Damit eignet sich Snap! gut für die Datenanalyse mit Schülerinnen und Schülern der Sekundarstufe I und das dabei erworbene Wissen und die erarbeiteten Kompetenzen – z.B. zur genauen Funktionsweise des map-Blockes – sollten sich anschliessend vergleichsweise gut auf eine Statistiksoftware wir R übertragen lassen.
Die folgenden Einschränkungen sollten aber beachtet werden:
Alle beschriebenen Blöcke funktionieren unter der Voraussetzung, dass die Daten sauber sind, d.h. keine fehlenden oder falschen Daten (z.B. Text statt Zahlen) enthalten. In dieser Hinsicht leistet R mehr, weil entsprechende Mechanismen teilweise schon eingebaut sind.
Da Snap! in einem Browser läuft und technisch auf eine JavaScript-Umgebung aufbaut, ist R in der Regel erstens schneller und kann zweitens auch mit wesentlich grösseren Datenmengen umgehen.
R verfügt mit seinen zahlreichen Erweiterungen natürlich über wesentlich mehr Statistikfunktionen als dies bei dem Allrounder Snap! der Fall ist.
Trotz dieser Einwände lohnt sich der Einsatz von Snap, denn …
Auch in R ist die Säuberung von Datensätzen mit grossem Aufwand verbunden und teilweise eine Aufgabe für Expertinnen und Experten.
Die Datenmengen, welche auf der Sekundarstufe I in der Regel bearbeitet werden, dürften weit unter dem technisch umsetzbaren Grenzen bei der Programmierung mit Snap! liegen.
Auf der Sekundarstufe I wird nur ein Bruchteil der statistischen Methoden benötigt, die in einem professionellen Umfeld verwendet werden. Ausserdem können die gewünschten Funktionen als Blöcke jederzeit nachprogrammiert werden.
Im Gegensatz zu R sind weitere Anwendungsfelder beispielsweise im Bereich Multimedia einfacher umzusetzen und bedürfen dafür auch nicht der vorgängigen Installation einer zusätzlichen Software auf den Geräten der Lernenden.
Insgesamt spricht also vieles für den Einsatz von Snap! auf der Sekundarstufe I und dies auch im Bereich der deskriptiven Statistik. Dass dies bisher wohl kaum geschehen ist, dürfte vor allem daran liegen, dass der Fokus der Volksschule bisher einerseits wenig auf der Programmierung lag, wobei die deutliche Abgrenzung zwischen Medien und Informatik im Lehrplan nicht unbedingt hilfreich ist, und wenn die eigentliche Informatik doch einmal im Vordergrund stand, sich diese auf die Umsetzung als „Informatik ohne Strom“ oder aber auf vergleichsweise banale Umsetzungen in blockbasierten Sprachen wie Scratch beschränkte, bei denen meist nur sehr einfache Konzepte der Informatik umgesetzt wurden.
Es ist zu hoffen, dass mit dem steigenden Bekanntheitsgrad von Snap! die dadurch eröffneten Möglichkeiten zunehmend auch im deutschsprachigen Raum eingesetzt und damit der künstliche Graben zwischen Medien und Informatik überwunden werden kann, denn die Datenanalyse mit Snap! ist nur eine von äusserst vielfältigen Anwendungsmöglichkeiten und die dabei erworbenen Erkenntnisse können anschliessend gut auch im Bereich der Medien genutzt und erweitert werden.
Die beschriebenen Blöcke können unter Data Science ausprobiert werden.
Snap! nutzt ein Koordinatensystem, welches sich am Modell der vier Quadranten orientiert: Sowohl die x- als auch die y-Koordinaten können negative und positive Werte annehmen. So können in der Grundeinstellung x-Werte von -240 (links) bis 240 (rechts) abgebildet werden, die y-Werte sind von 180 (oben) bis -180 (unten) sichtbar. Der Koordinatenursprung liegt also im Zentrum.
Abbildung von Punkten im Koordinatensystem von Snap!.
Dies im Gegensatz zu vielen anderen Programmiersprachen, wo der Koordinatenursprung (0, 0) häufig in der oberen linken Ecke liegt.
Wie gross der abgebildete Bereich tatsächlich ist, kann über die Einstellung zur Bühnengrösse (stage) festgelegt werden.
Die Auflösung des Ausgabefensters (stage) kann in Snap! angepasst werden.
Diese Darstellung der Koordinaten und die unterschiedlichen Bildschirmgrössen in Snap! sollte man bei der Programmierung entsprechender Grafiken berücksichtigen. Sonst werden beispielsweise Grafiken mit ausschliesslich positiven Koordinaten nur in einem Viertel des Bildschirms dargestellt.
Bildet man beispielsweise die Quadrate der natürlichen Zahlen ab, wird nur ein Viertel des Bildschirms genutzt.
Noch vertrackter wird es, wenn man während der Programmierung die Auflösung ändert oder es mit sehr grossen oder kleinen Zahlen zu tun hat. Dann muss man jedes Mal die entsprechenden Koordinaten umrechnen.
Dies von Hand zu tun ist nur eine Lösung, welche sinnvoll ist, wenn man Snap! kaum jemals für die Darstellung von Daten benötigt. Bei häufigerer Verwendung liegt es nahe, eine entsprechende Umrechnungsroutine in Snap! selbst zu schreiben.
Schülerinnen und Schüler scheitern meist daran, dass dies keine ganz einfache Aufgabe ist. Die folgenden Schritte erklären, wie man zu einer Lösung kommt, welche solche Darstellungsprobleme endgültig beseitigen. Dabei lohnt es sich, schrittweise vorzugehen.
Im einfachsten Fall beginnen sowohl der Datenbereich als auch die Bildschirmdarstellung bei 0, wie die folgende Grafik zeigt.
Wenn beide Zahlenbereiche bei 0 beginnen, ist die Aufgabe schnell gelöst.
Der Datenbereich in der Grafik reicht von 0 bis 6, auf dem Bildschirm können die Werte 0 bis 12 abgebildet werden. Um die Zahlen von einer Menge in die andere umzurechnen, vergleichen wir die Spannweiten der beiden Bereiche. Die Spannweite auf dem Bildschirm ist doppelt so gross wie die Spannweite des Datenbereiches. Es genügt in diesem Fall also, alle Datenwerte mit 2 zu multiplizieren, um die korrekte Position auf dem Bildschirm zu erhalten, wir erhalten also folgende Werte:
0 ⟶ 0 (kleinster Wert)
6 ⟶ 12 (grösser Wert)
2 ⟶ 4 (grüner Punkt)
Etwas kompliziert wird es, wenn der Datenbereich nicht bei 0 beginnt, dann muss die Umrechnung angepasst werden:
Wenn der Datenbereich nicht bei Null beginnt, reicht eine einfache Multiplikation nicht mehr aus.
Aus der Grafik erkennen wir sofort, dass die Umrechnung des Wertes für den grünen Punkt nicht mehr durch eine einfache Multiplikation erfolgen kann, weil dieser bei den Daten in der Nähe des grössten Wertes liegt, während dies in der Abbildung definitiv nicht der Fall ist. Eine kurze Überprüfung anhand der Extremwerte zeigt, was zu tun ist:
-2 ⟶ -4 statt 0
Differenz zum tatsächlichen Wert: -4
4 ⟶ 8 statt 12
Differenz zum tatsächlichen Wert: -4
Die Differenz des kleinsten Wertes aus dem Datenbereich beträgt aber nur -2, die -4 ergeben sich erst mit der erneuten Multiplikation: Die Werte aus dem Datenbereich müssen also zuerst multipliziert werden und dann um den mit dem gleichen Faktor multiplizierten Unterschied zwischen dem Minimum der Daten und Null korrigiert werden. So erhalten wir:
-2 ⟶ -4 + 4 = 0 (kleinster Wert)
4 ⟶ 8 + 4 = 12 (grösser Wert)
2 ⟶ 4 + 4 = 8 (grüner Punkt)
Nun ist es aber auch möglich, dass der Bildschirmbereich gegenüber dem Nullpunkt so wie bei Snap! verschoben ist.
Wenn auch noch der Bildschirmbereich verschoben ist, dann müssen die bisherigen Korrekturen noch einmal erweitert werden.
Wieder helfen die Minimal- und Maximalwerte weiter, um zu verstehen, was für eine zusätzliche Korrektur notwendig ist.
Bei der letzten Korrektur muss also noch die Differenz vom Minimum des Bildschirms zum Nullpunkt berücksichtigt werden.
Werden alle Korrekturen eingerechnet, dann funktioniert die Umrechnung von einem Datenbereich in den anderen.
Eine Überprüfung ergibt:
-2 ⟶ -4 ⟶ 0 ⟶ -2 (kleinster Wert)
4 ⟶ 8 ⟶ 12 ⟶ 10 (grösster Wert)
2 ⟶ 4 ⟶ 8 ⟶ 6 (grüner Punkt)
Hier noch einmal die ganzen Ausführungen als Erklärfilm:
Für die Abbildung eines beliebigen Datenpunktes auf dem Bildschirm gilt deshalb folgende Formel:
Datenwert x Quotient der Differenzen + Differenz vom minimalen Datenwert zum Nullpunkt multipliziert mit dem Quotienten der Differenzen + Differenz vom minimalen Bildwert zum Nullpunkt
In Snap! kann ein entsprechender Block so geschrieben werden, wobei einige Hilfsvariablen die Sache erleichtern:
Mit diesem Block können Daten so umgerechnet werden, damit die Darstellung am Bildschirm optimal ist.
Greifen wir dazu noch einmal das Beispiel der Quadratzahlen auf, deren Bildpunkte beim ersten Versuch alle im 1. Quadraten landeten. Die Umrechnung kann entweder beim Zeichnen der Grafik oder schon anhand der darzustellenden Daten erfolgen.
Mit diesen Befehlen können beliebige Daten umgerechnet werden.
Der erste Block in der Grafik (grau) führt die eigentliche Umrechnung für einen Wert aus.
Der zweite Block (blau) liefert die Breite der Bühne (Bildschirm) zurück. Eine entsprechende Möglichkeit gibt es für die Bildschirmhöhe. Dieser Wert muss durch 2 geteilt werden, da die Differenz des minimalen und maximalen Wertes doppelt so gross ist wie der Abstand des Minimalwertes zum Ursprungspunkt.
Der dritte Befehl (orange) nimmt als Argument eine Liste entgegen und wendet dann auf jedes Element die Befehle an, die im grauen Ring enthalten sind.
Der vierte Block (ebenfalls orange) wählt das angegebene Element aus einer Liste aus.
Der grosse Block führt deshalb folgende Befehle aus:
Der Datensatz wird genommen und in zwei Teillisten mit der ersten und zweiten Spalte aufgeteilt.
Für beide Spalten werden alle enthaltenen Werte gemäss den Parametern im Umrechnungsblock so berechnet, dass diese auf den Bildschirm passen.
Damit die Daten nicht am Rand des Bildschirms landen, wurden bei den Daten ein etwas grösserer Bereich angegeben. So ist es dann allenfalls noch möglich, die Grafik mit zusätzlichen Informationen (Titel, Achsen, Legenden) anzureichern.
Hält man sich an dieses Vorgehen, können Daten auf einem beliebig grossen Bildschirm passend ausgegeben werden. Ausprobieren kann man dies unter Daten umrechnen. Dazu klickt man nach dem Öffnen auf die Schaltfläche „see code“. In der eingebundenen Version unten klickt man stattdessen auf das Augensymbol oben links.